


| This article includes: |
| What are the limitations of test-time computation? Strategies in LLMs Fractional Reasoning: Introduction As a model-independent framework that does not require training. Techniques for latent state manipulation Use of reasoning prompts as well as adjustable scales. Scaling benefits based on depth and breadth This is demonstrated in GSM8K and MATH500. Evaluation Results Showing FR superiority to Best-of N and Majority Vote. Analysis of FR’s behaviour across different models, including DeepSeek-R1. |
Introduction: Problems with uniform reasoning during inference
The performance of LLMs has improved in many domains. Test-time computation is a key factor. The approach improves reasoning by allocating additional computational resources. For example, it can generate multiple candidates responses, select the best one or refine answers through self-reflection. Currently, test-time computation strategies apply the same reasoning depth to all questions, regardless of their complexity or structure. Reasoning needs can be highly variable. In fact, under- or over-thinking and reflection may lead to poorer answers or unnecessarily high computational costs. LLMs should be able to adjust their level of reasoning or reflection on a dynamic basis.
Previous work: Representation and Latent Steering
There are several methods that have been explored to improve LLM through latent state control and inference time scaling. Chain-of-Thought prompting techniques guide models in decomposing complex problems into steps for better reasoning. The outcome reward model (ORM) and the process reward model (PRM) assess generated responses on their correctness or internal reasoning. In addition, the representation engineering method uses steering vectors within LLM latent space for controlled generation. Methods like ICV extract latent vectors during demonstrations and steer internal states when inference is made.
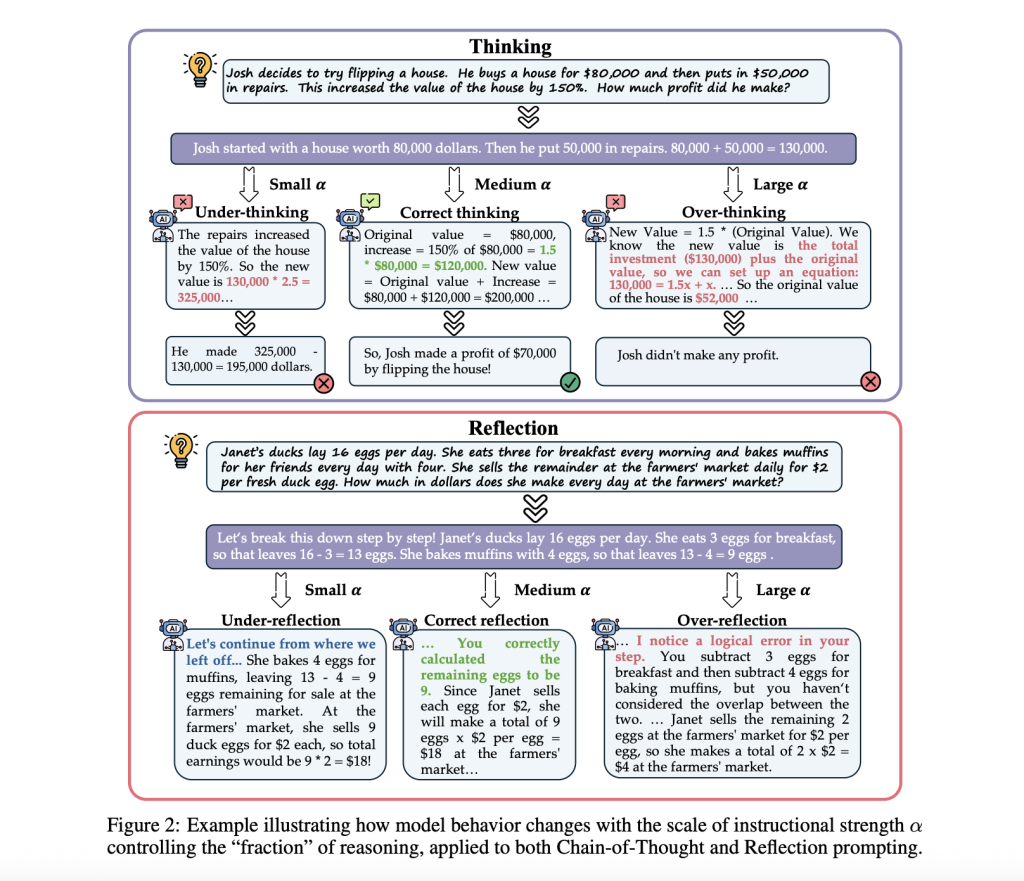
The Framework Proposed: Fractional Inference for Adaptive Reasoning
Stanford University researchers have developed Fractional reasoning (FR), a model-agnostic and training-free framework to improve test-time computation through adaptive reasoning. FR changes reasoning behavior directly by modifying a model’s internal models, extracting latent shifts induced by reasoning-promoting factors such as CoT and reflection prompts and then applying these shifts with a tunable scale factor. The models can adjust their reasoning depth during inferences without having to modify the text input or fine-tune. The two most important forms of scaled test times are supported and enhanced by FR:
Benchmarking Performance Gains in Reasoning Tasks
FR is assessed on three benchmarks requiring multi-step reasoning, GSM8K (GSM 8K), MATH500 (MATH500), and GPQA. The test sets used in the evaluation are GSM8K for MATH500, and GPQA for diamond split. Main experiments use two competitive open-source instruction-tuned models: Qwen2.5-7B-Instruct and LLaMA-3.1-8B-Instruct, both of which demonstrate strong reasoning capabilities and provide access to the latent state representations required by the proposed method. Standard test-time methods outperform FR on all models and benchmarks. This shows that FR can improve performance. By adjusting the prompts, you can explore the entire solution space and increase the efficiency of test-time computation methods.
The Behavior of Fractional Reasoning and its Model-Agnostic Generally
The researchers analyzed FR in order to better understand the model’s behavior, its generality, and various metrics. According to the analysis, increasing the scaling parameter led to more complex multi-step reasoning and longer outputs. It is clear that the framework guides model behavior in a predictable way. FR remains effective even when applied to reasoning-specialized models such as DeepSeek-R1-Distill-Qwen-7B, improving accuracy over standard prompting baselines and showing its generality across both general-purpose and specialized LLMs. Analysis of performance scaling shows that improvements are consistent with increasing numbers of generations. In addition, FR is more accurate across all sampling budgets than the majority vote baseline.
Conclusion: More dynamic and efficient LLM Inference
Stanford University researchers have developed Fractional Reasoning (FR), a framework for improving test-time computing through adaptive control in LLMs. The framework offers a general, interpretable method for more accurate and efficient computation during inference. The framework relies on predefined reasoning and does not automatically select scaling factors. Future research will focus on adaptive policies that allow for dynamic inference.
| Take a look at the Paper. The researchers are the sole credit holders for this work. Ready to connect with 1 Million+ AI Devs/Engineers/Researchers? MarkTechPost helps NVIDIA, LG AI Research and other top AI companies reach their audience. [Learn More] |

Sajjad A. Ansari, a student in the final year at IIT Kharagpur. Tech enthusiast Sajjad is interested in the applications of AI, with an emphasis on their impact and real-world implications. He strives to make complex AI ideas clear and understandable.