

, a hardware-aware strategy for training and inference, delivers up to 2.6x the throughput of matched TP+SP benchmarks")
Memory management is the key to training and serving transformer models in large scale. Each GPU has a limited amount of VRAM. As model sizes and contexts lengths increase, engineers are forced to constantly make decisions about the best way to allocate work to hardware. Every GPU in a cluster has a fixed amount of VRAM, and as model sizes and context lengths grow, engineers are constantly forced to make trade-offs about how to distribute work across hardware. new technique The following is a list of the most recent and relevant articles. ZyphraCall it Tensor and Sequence Parallelism offers a way to rethink that trade-off — and in benchmark tests on up to 1,024 AMD MI300X GPUs, it consistently delivers lower per-GPU peak memory than any of the standard parallelism schemes used today, for both training and inference workloads.

It is TSP that solves the problem
You must understand TSP’s two parallelism strategies before you can understand its significance.
Tensor Parallelism Model weights are split across the GPUs. Each GPU of the TP Group holds a small fraction of a weight matrix if you use an MLP or attention layer. This directly reduces the per-GPU memory occupied by parameters, gradients, and optimizer states — the ‘model state’ memory. The trade-off is that TP requires collective communication operations (typically all-reduce or reduce-scatter/all-gather pairs) every time a layer is computed. The cost of this communication increases with the length of a sequence.

Sequence Parallelism It takes a completely different approach. It splits input tokens across the GPUs instead of dividing weights. This reduces the cost and activation memory of computing attention by allowing each GPU to process only a small fraction of tokens. SP, however, leaves all model weights replicated across every GPU. This means that model state memory remains the same no matter how many GPUs are added to an SP group.
Standard multi-dimensional paralelism combines TP and SPL by placing them orthogonally on the mesh of a device. If you want a TP degree of T and an SP degree of Σ, your model replica consumes T.Σ GPUs. In two ways, this is very expensive. This is expensive in two ways. Second, if T.Σ is large enough to span multiple nodes, some collective communication has to travel over slower inter-node interconnects like InfiniBand or Ethernet instead of the high-bandwidth intra-node fabric, such as AMD Infinity Fabric or NVIDIA NVLink. The other baseline is Data Parallelism, which avoids model parallel costs but duplicates the model state across all devices. This makes it unsuitable for models with long or large contexts.
How to Fold a Book
TSP is based on the idea of parallelism fold: it allows TP and SPD to be placed onto the same D-sized device mesh axis, but simultaneously hold 1/D each of the weights for the models and 1/D the sequence of tokens. Because both are sharded across the same D GPUs, the per-device memory footprint decreases by 1/D for both parameter memory and activation memory — something no single standard parallelism scheme achieves on its own. TSP is therefore the only scheme that simultaneously reduces weight-proportional memory (parameters, gradients, optimizer states) and activation memory by the same 1/D factor on a single axis without requiring a two-dimensional T.Σ device layout.
To complete the forward pass of each layer, a GPU that only knows a portion of its weights and sequence must coordinate with another GPU. TSP has two separate communication schedules for this. One is for attention, and another for gated MLP.
TSP iterates through weight shards to get attention. Each step, a GPU broadcasts to the other GPUs of the group its packed attention weights (WQ WK WV and WO). Each GPU applies these weights on its sequence tokens in order to calculate local Q, V, and K projections. FlashAttention must have access to all key-value contexts, so the K and V local tensors from the TSP are collected and reordered in a zigzag scheme. It is important to balance the workload of causal attention across all ranks. The zigzag scheme ensures this, because tokens at later levels are more likely to be focused on prefixes with larger sizes.
TSP utilizes a ring scheduling for the gated MLP. Every GPU begins with a local shard of gate, up and downward projections. The weight shards are sent and received from the TSP via point-topoint operations. Each GPU then accumulates local partial outputs as they arrive. Critically, this eliminates the all-reduce that standard TP requires for MLP output — the sequence stays local, and only the weights move. This ring overlaps weight transfers and GEMM computation so that communication occurs in the background as the GPU computes.
Memory and Processing Results
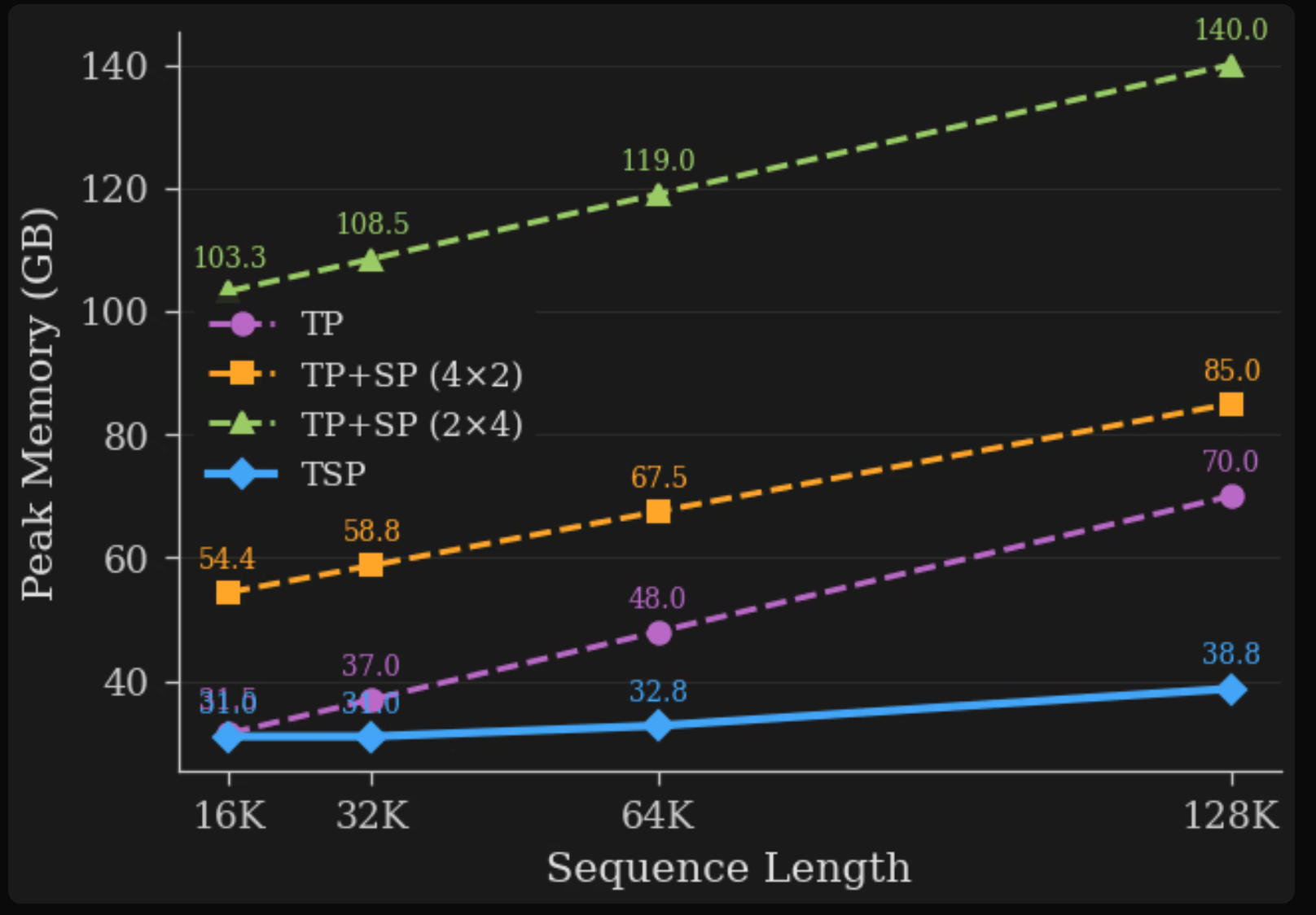
TSP achieved the lowest memory peak at all points when tested on an 8-GPU MI300X Node. Because model-state memories dominate at short context, the TSP and TP performance are almost equal. By 128K, however, things change dramatically. TSP is using 38.8 GB on each GPU as opposed to 70.0 GB with TP. These theoretical numbers are all based on the 7B dense transformer model, which is a reference for decoding only (hidden dimension H=4096 with 32 layers and query heads. 32 KV Heads, FFN Expansion Factor F=4; bf16 Precision). This allows a consistent baseline to be used when comparing schemes.
TSP’s performance on 128 complete nodes (1 024 MI300X GPUs), compared to matched TP+SP baselines, is consistently superior. TSP can achieve 173 millions tokens in a second with a D=8 folded degree and a sequence length of 128K, compared to 66.30 for a matched TP+SP base (roughly a 2.6x increase). As parallelism increases, so does the benefit.
The Practicality of Trade-offs
TSP increases the total volume of communication compared with TP. It adds a weight-movement term per layer on top of the same activation-proportional K/V all-gather that SP uses. However, the research team shows that when batch size B and sequence length S satisfy BS > 8h (where h is the model’s embedding dimension), TSP’s forward communication volume is competitive with TP’s. In most training scenarios and inferences, this condition is satisfied.
Zyphra’s team stresses that the two aren’t the same. It depends on the latency or bandwidth of collectives, as well as how much traffic is overlapped by matrix multiplication. Weight transfers are placed behind GEMM operations in their implementation pipelines so as to not increase critical path time.
TSP was not intended to replace TP, TP+SP, or SP+TP in all situations. This is intended to serve as an extra axis within the multidimensional parallelism space. The parallelism is built in a way that’s orthogonal with data parallelism. TSP can be inserted into existing parallelism layouts to replace the need for model-parallel groupings across slow inter-node connections.
What you need to know
- Zyphra’s Tensor and Sequence Parallelism combines tensor and sequence parallelism into a single device mesh axis. Each GPU can hold 1/D weights of the models and 1/D tokens at the same time, which reduces memory usage for training and inference.
- TSP is the only parallelism scheme that reduces both weight-proportional memory (parameters, gradients, optimizer states) and activation memory by the same 1/D factor on a single axis, without requiring a two-dimensional T.Σ device mesh.
- Empirical results on a single 8-GPU MI300X node show TSP uses 38.8 GB per GPU at 128K sequence length, compared to 70.0 GB for TP and 85.0–140.0 GB for TP+SP configurations.
- TSP can achieve 173 millions tokens/second at large scale (1.024 MI300X, 128K context with D=8) compared to 66.30 for the matched baseline TP+SP. This is approximately a 2.6% throughput improvement.
- TSP is composed orthogonally by pipeline, expert and data parallelism. It’s best for memory-constrained, long-context training and inference workloads, where removing weight and activation repetition outweighs any added communication volume.
Check out the Paper You can also find out more about the following: Technical details. Also, feel free to follow us on Twitter Join our Facebook group! 130k+ ML SubReddit Subscribe now our Newsletter. Wait! What? now you can join us on telegram as well.
You can partner with us to promote your GitHub Repository OR Hugging Page OR New Product Launch OR Webinar, etc.? Connect with us