


AI can make medical expertise more accessible. However, current evaluations are often flawed because they rely on static, simplified scenarios. The real clinical setting is more dynamic. Doctors adapt their approach to diagnosis by asking questions, interpreting information and changing it as they go. Iterative processes help them to refine hypotheses and weigh the costs and benefits associated with tests. They also avoid rushing into conclusions. Although language models performed well on structured tests, they don’t represent the complexity of real life, which is often overlooked by static assessments.
For decades, medical experts have been exploring the problem-solving aspects of medicine. The first AI systems relied on Bayesian frameworks that guided sequential diagnoses within specialties like pathology and trauma. These approaches were not without their challenges, however. They required extensive expert input. Recently, studies are shifting to using language models as a basis for clinical reasoning. These benchmarks, which were once static multiple-choice tests, have now become saturated. AMIE, NEJM CPC and other projects have introduced more complex cases but remained reliant on vignettes. Fewer newer approaches capture the complex nature of cost-sensitive, real-time diagnostic decisions.
Researchers from Microsoft AI created SDBench to better represent real-world clinical thinking. The benchmark is based on real diagnoses from the New England Journal of Medicine. Doctors or AI systems are required to interact with each other and ask questions before reaching a diagnosis. The language model is a gatekeeper that only reveals information when it’s requested. In order to enhance performance, the company introduced MAI DxO, a system orchestrator co-designed by physicians, which simulates an online medical panel for selecting high-value and cost-effective test. It achieved 85.5% accuracy when paired with OpenAI’s O3 model, while reducing diagnostic cost.
The Sequential Diagnosis Benchmark (SDBench) was built using 304 NEJM Case Challenge scenarios (2017–2025), covering a wide range of clinical conditions. The cases were transformed into interactive simulations where agents from diagnostic agencies could make final diagnoses, ask for tests or request questions. The Gatekeeper was powered by a clinical rule-based language model, and responded with realistic details of the case or consistent but synthetic findings. A Judge model evaluated diagnoses using physician-authored criteria that focused on clinical relevancy. CPT codes, pricing information and real world diagnostic decisions were used to calculate costs.
The researchers tested various AI agents for diagnostic accuracy on the SDBench. They discovered that MAI-DxO outperformed physicians and off-theshelf AI models. MAI-DxO was built using o3 and delivered greater accuracy for lower cost through decision-making and structured reasoning. The MAI-DxO, built on o3, achieved an accuracy of 81.9% at $4.735 per test case compared with O3’s standard 78.6% for $7.850. This system also showed strong generalizability across models. It significantly improved weaker model and assisted stronger models to use resources more efficiently.
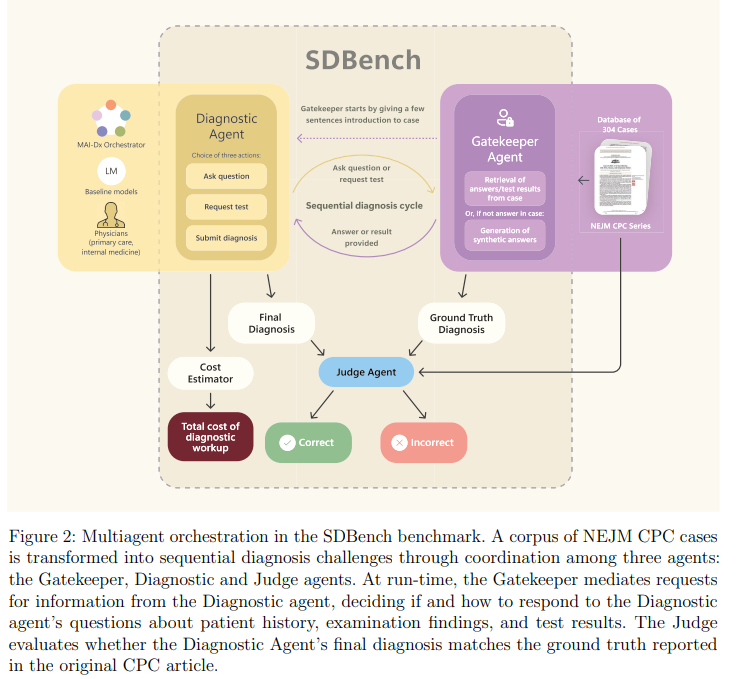
Conclusion: SDBench provides a new benchmark for diagnostics that converts NEJM CPC scenarios into realistic interactive challenges. AI or doctors are required to interact with the cases, asking questions, ordering tests and making diagnoses. It mimics clinical decision making, unlike static benchmarks. Researchers also developed MAI-DxO – a simulation model for diverse medical personas that can achieve a high level of diagnostic accuracy while reducing costs. Although the current results look promising, they are limited by the absence of realistic conditions. The future work will test the system on real patients in low resource settings and clinics. This could have a global impact for health and be used to educate medical students.
Sana Hassan has a passion for applying AI and technology to real world challenges. Sana Hassan, an intern at Marktechpost and dual-degree student at IIT Madras is passionate about applying technology and AI to real-world challenges.