


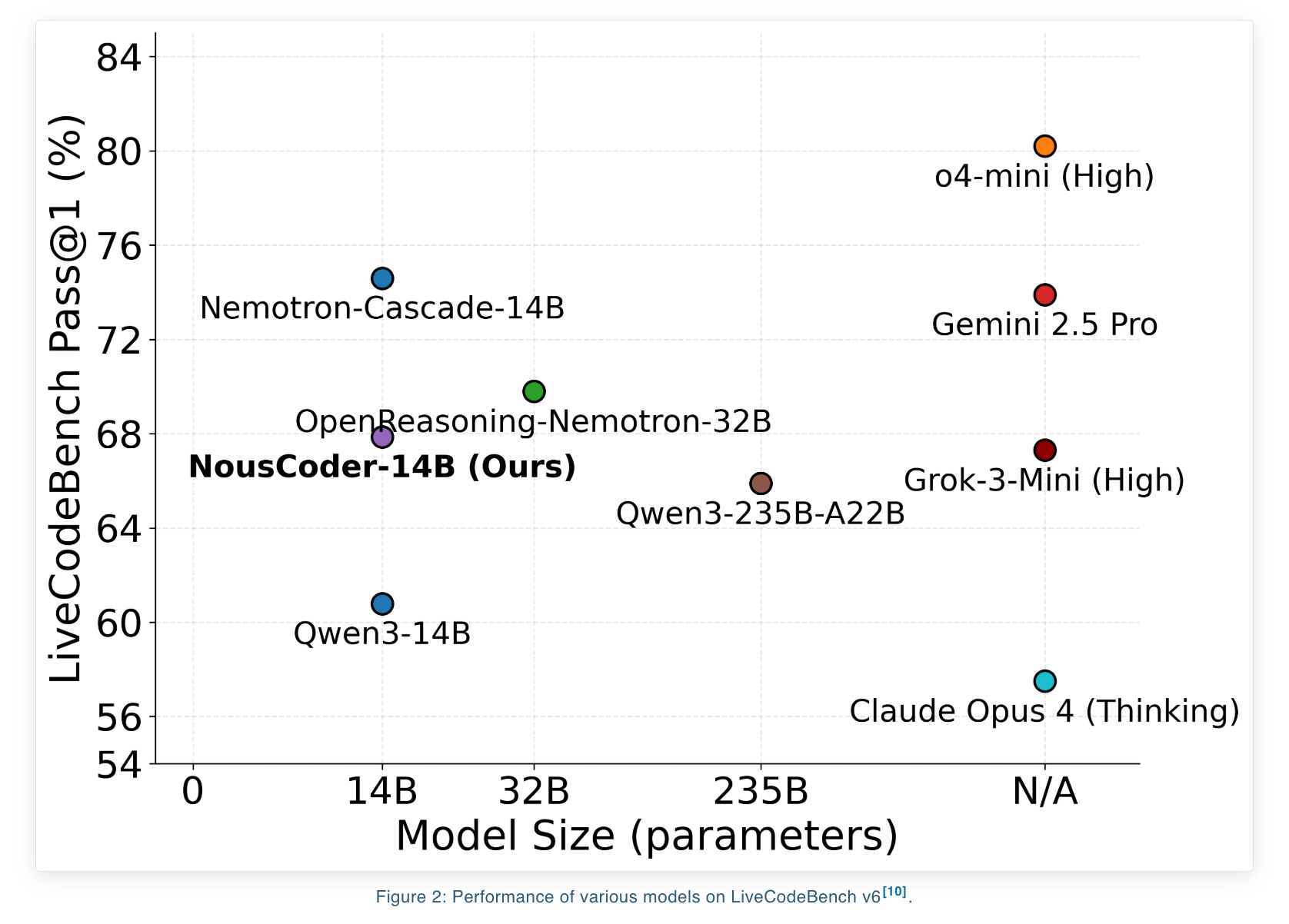
Nous Research introduced NousCoder-14B – a competitive programming model for olympiad competitions that was post-trained on Qwen3-14B with reinforcement learning. The model achieves 67.87 per cent accuracy on the LiveCodeBench benchmark which includes problems between 08/01/2024 and 05/01/2025. The model’s accuracy is also 7.08 points above the Qwen3-14B benchmark of 60.79 on the same test. Researchers trained their model over four days on 48 B200 GPUs, solving 24k verified coding problems. They then released weights on the Hugging Face website under an Apache 2.0 license.

What Pass@1 is and how it relates to benchmarking
LiveCodeBench is designed to evaluate competitive programming. Test splits are divided into 454 questions. This training set is based on the DeepCoder-14B Project from Agentica and Together AI. The training set combines problems that were created by TACO Verified and PrimeIntellect SYNTHETIC 1 before 07/31/2024.
Only competitive style programming tasks are included in the benchmark. A solution to each problem must meet strict memory and time limits, and pass an extensive set of input/output tests. It is defined as the percentage of problems for which the program generated first passes all tests. This includes time and memory restrictions.
Build a dataset for execution using RL
The datasets for the training consist of problems which can be checked. Every problem is accompanied by a number of test cases and an implementation. This training set includes 24k exercises drawn from the following sources:
- TACO Verified
- PrimeIntellect SYNTHETIC 1,
- LiveCodeBench Problems that occur prior to 07/31/2024
LiveCodeBench V6 has 454 issues between the dates of 08/01/2024 to 05/01/2025.
The problem is complete, with an input format, output formats, and tests. It is essential for RL to have this setup because it provides a cheap binary reward once the code runs.
Atropos and Modal – a RL Environment
Atropos is used to build the RL environment. It generates Python code by using LiveCodeBench’s standard prompt format. The reward for each rollout depends on the results of test cases:
- Rewards 1 for code that passes the entire test case.
- Reward −1 when the code outputs a wrong answer, exceeds a 15 second time limit, or exceeds a 4 GB memory limit on any test case
The team has used Modal to create an automatic sandbox that allows them execute code they are not confident about in a safe and secure manner. The system launches a Modal Container per rollout, in what the team of researchers calls the “used setting”. Each container runs the test cases associated with that rollout. The RL loop is kept stable by not mixing the training and verification computations.
Inferences and verification are also piped by the research team. The inference worker sends the completed generation to a Modal verifyor and starts immediately a new one. The design uses Modal containers to keep the training loop compute bound, rather than verification bound.
Three parallel verification strategies are discussed by the team. One container is used per issue, another per deployment, and a third per test. The container launch overhead is the reason they avoid setting the container per test case. Instead, each container will evaluate many test cases before focusing on the most difficult ones. The system will stop the verification process if any of them fail.
GRPO Objectives, DAPO and GSPO+
NousCoder-14B is based on Group Relative Policy Optimization, which doesn’t require a value model. In addition to GRPO, the research team also tested 3 objectives: Dynamic sAmpling Policy Optimization, Group Sequence Policy Optimization and a modified GSPO called GSPO+.
Each of these objectives has the same definition for advantage. Each rollout’s advantage is equal to the average and standard deviation for rewards within the group, normalized. DAPO weights and clips tokens according to their importance. Introduces three major changes to GRPO
- The clip-higher rule increases the exploration for tokens with low probabilities
- The policy that gives equal weight to each token in a token-level gradient loss
- The dynamic sampling method is a way to eliminate groups of all the correct answers or all the incorrect ones because there’s no advantage in them.
GSPO shifts the weighting of importance to the level of sequence. The sequence importance ratio is a sum of token ratios for the entire program. GSPO+ retains sequence corrections, but rescales all gradients in order to weight tokens equally no matter the sequence length.
LiveCodeBench version 6 shows that the difference between these two objectives is modest. DAPO reaches a Pass@1 score of 67.87 per cent at a length of 81.920 tokens. GSPO, GSPO+, and GSPO reach 66.26 and 66.52 respectively. All 3 objectives are clustered around the 63 percent pass@1 at 40,960 tokens.
The context filtering and extension iterative is a long-term process.
Qwen3-14B can support long context, and training is based on an iterative schedule of context extensions. Team first train the model in a context of 32k and continue to train at Qwen3-14B’s maximum 40k context. The team selects the checkpoints with the best LiveCodeBench scores at the 40k context.
Overlong filtering is a key trick. If a generated programme exceeds the context maximum window, its benefit is reset to zero. The rollout is removed from the gradient signals, rather than being penalized. This approach, according to the research team, avoids forcing a model towards shorter solutions solely for optimization purposes and maintains quality when context length is scaled at test time.
What you need to know
- The Qwen3-14B-based model, trained using execution-based RL (Real Life), achieves 67.87 per cent Pass@1 in LiveCodeBench version 6, a gain of 7.08 points over Qwen3-14B’s baseline 60.79percent on this benchmark.
- The model has been trained with 24k coding tasks that are verifiable from TACO, PrimeIntellect, SYNTHETIC-1 or LiveCodeBench pre-07 31 2024. Finally, it is evaluated using a LiveCodeBench 6 test set of disjoint 454 LiveCodeBench problems between 8/01/2024 and 5/01/2025.
- Atropos is used for the RL set-up, which includes Python solutions running in sandboxed container, a reward system of one for solving each test case and minus one for failures or exceeding resource limits, as well as a pipelined approach wherein inference and verifying run asynchronously.
- Group Relative Policies Optimization Objectives DAPO GSPO GSPO+ all work on the group-normalized reward system and have similar performances. DAPO achieves the best performance at the long context code RL of 81.920 tokens.
- This training includes YaRN-based context extension to 81.920 tokens at evaluation, as well as overlong rollout filters for stability. It ships with a reproducible, open stack that uses Apache 2.0 weights.
Take a look at the Model Weights The following are some examples of how to get started: Technical details. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! What? now you can join us on telegram as well.
Asif Razzaq, CEO of Marktechpost Media Inc. is a visionary engineer and entrepreneur who is dedicated to harnessing Artificial Intelligence’s potential for the social good. Marktechpost is his latest venture, a media platform that focuses on Artificial Intelligence. It is known for providing in-depth news coverage about machine learning, deep learning, and other topics. The content is technically accurate and easy to understand by an audience of all backgrounds. This platform has over 2,000,000 monthly views which shows its popularity.