


Reinforcement Learning for Optimizing LLMs in Human Alignment
In order to make large language models more human-friendly, they often need a second phase of alignment. Reinforcement learning is a key component of this phase. It allows models to be based upon human feedback, or tasks that are correct. The models are fine-tuned to better align with the user’s expectations. This makes them suitable for applications that require precise mathematics or instruction.
Challenges in Choosing Offline vs. Online Reinforcement Learning Strategies
The choice of the best method to fine-tune is a difficult one. Training methods fall into two extremes—offline approaches that depend on static, pre-generated data and fully online approaches that continuously update with each new interaction. Both methods have their own challenges. The performance of offline models is limited because they cannot be adapted during training. On the other hand, online models require more computing resources. This choice is further complicated by the need to ensure that models are able to perform both in mathematical tasks (verifiable), and also open-ended, non-verifiable ones.
Algorithms for Alignment: DPO & GRPO
In the past, models were aligned using tools such Direct Preference Optimization(DPO) or Group Relative Policy Optimization(GRPO). DPO is designed for offline use and works with data pairs based on preferences. The simplicity of the method and its data efficiency are valued, but it lacks adaptability. GRPO, which is based upon the PPO algorithm, handles fine-tuning online by comparing output groups to calculate relative advantages. GRPO is dynamic and adapts to reward systems in real time. However, the fact that it’s based on policy increases computation load and requires more experimentation.
The Balanced Alternative to LLM Alignment
Meta’s and NYU’s research explored how to circumvent these limitations by using a semi-online setup. It modulates the rate at which model components for generation and training are updated, as opposed to updating them at each training stage, like in online setups, or never, like in offline ones. Semi-online methods strike a balance by changing the rate of synchronization. The researchers designed this method to decrease training time, while still maintaining high model adaptability. They could also apply DPO and GRPO models with task-specific rewards in a flexible way.

Mathematics and Instructional Following
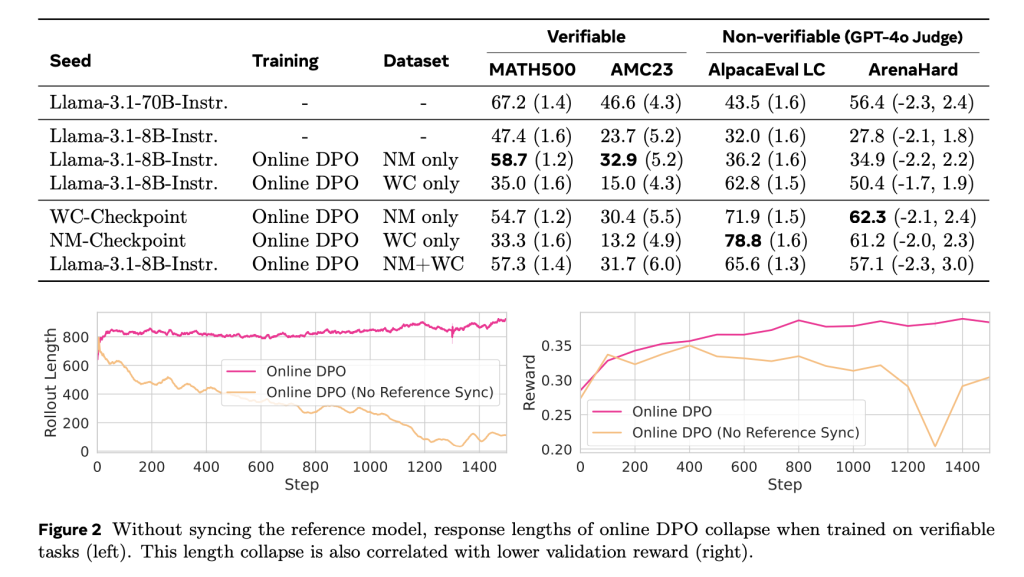
The methodology involved fine-tuning the Llama-3.1-8B-Instruct model using two types of tasks: open-ended instruction following and math problem-solving. In order to assess non-verifiable challenges, the Athene RM-8B reward system was applied, which assigned scalar values for each user prompt. The team used the NuminaMath data set in combination with the Math-Verify Toolkit to verify whether the generated outputs match the expected ones. In order to compare different synchronization settings, the team ran training experiments using 32 NVIDIA HD200 GPUs.
Performance Improvements for Both Verifiable And Non-Verifiable Work
There were differences in performance. Math500 showed that the accuracy of the DPO was 53.7% for the offline DPO and 58.9% with the semi-online DPO using a synchronization time interval of 100. Online DPO results were similar to GRPO, at 58.7% versus 58.1%. The NuminaMath benchmark showed similar trends. Offline DPO scored 36.4% and semi-online variations increased that to 39.4%. Not only math tasks showed performance improvements. Models trained using mixed rewards performed better when non-verifiable task benchmarks were used with AlpacaEval and Arena-Hard. When verifiable as well as non-verifiable incentives were combined in a training scenario, the average score was higher.
The Reinforcement learning in LLMs: A flexible and scalable approach
The study shows that the fine tuning of large language models doesn’t require a strict adhesion to offline or online settings. The research team at Meta and NYU introduced a flexible training scheme that increased efficiency, while maintaining or even improving performance. These results demonstrate that carefully balancing the reward type and frequency of training synchronization leads to models with high performance across different task types.
Take a look at the Paper. This research is the work of researchers. Also, feel free to follow us on Twitter, Youtube You can also find out more about the following: Spotify Don’t forget about our 100k+ ML SubReddit Subscribe now our Newsletter.
Nikhil works as an intern at Marktechpost. He has a dual integrated degree in Materials from the Indian Institute of Technology Kharagpur. Nikhil, an AI/ML fanatic, is constantly researching AI/ML applications for biomaterials and other biomedical fields. Material Science is his background. His passion for exploring and contributing to new advances stems from this.