


Most text-to video models produce a clip after a prompt, and then stop. These models don’t maintain a world state in which actions continue to arrive. PAN is a model developed by MBZUAI’s Institute of Foundation Models to close this gap. It acts as a world model which predicts the future state of world as video, based on natural language and history.

Video generators to world simulation interactive
PAN can be defined as an interactive, general world model with a long-horizon. It maintains an internal latent state that represents the current world, then updates that state when it receives a natural language action such as ‘turn left and speed up’ or ‘move the robot arm to the red block.’ It then converts this updated state to a video clip that shows its result. This cycle continues, with the result that the same state of world evolution occurs in multiple steps.
PAN can now support simulations in open domains, based on action conditions. It is able to roll out different counterfactual outcomes for various action sequences. PAN is a simulator that allows an external agent to query it, view predicted futures and make decisions based on them.
GLP architecture: separating the what from the how
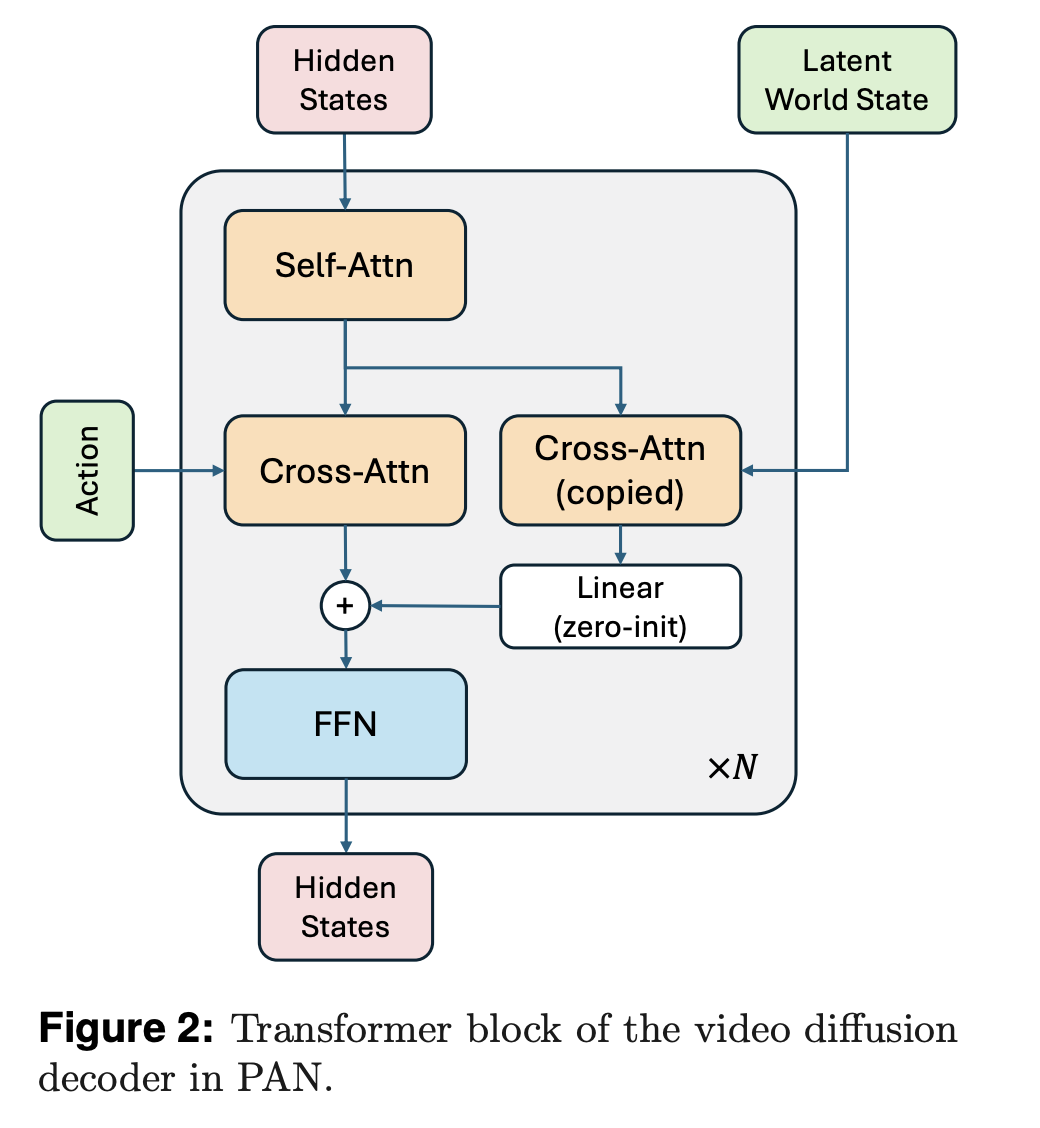
GLP architecture is at the core of PAN. GLP is a separate world dynamic from visual rendering. A vision encoder first maps video or image frames to a latent state of the world. The second step is an autoregressive dynamic backbone, which uses a large model of language to predict the latent state based on the history and action. The video decoder will then reconstruct the video from this latent state.
In PAN, the vision encoder and backbone are built on Qwen2.5-VL-7B-Instruct. The vision tower tokenizes the frames and creates structured embeddings. The language core runs over the history of actions and world states plus the learned query tones and produces the latent image of the next global state. They are located in the VLM’s shared multimodal environment, where they help ground dynamics both in text and in vision.
The video decoder has been adapted to Wan2.1T2V-14B which is a high quality video generator. The team trained this decoder using a flow-matching objective. They used 1,000 denoisings steps, and the Rectified Flow Formulation. Decoders condition on the latent predicted world state as well as the natural language text.
Casal Swin and sliding window DPM
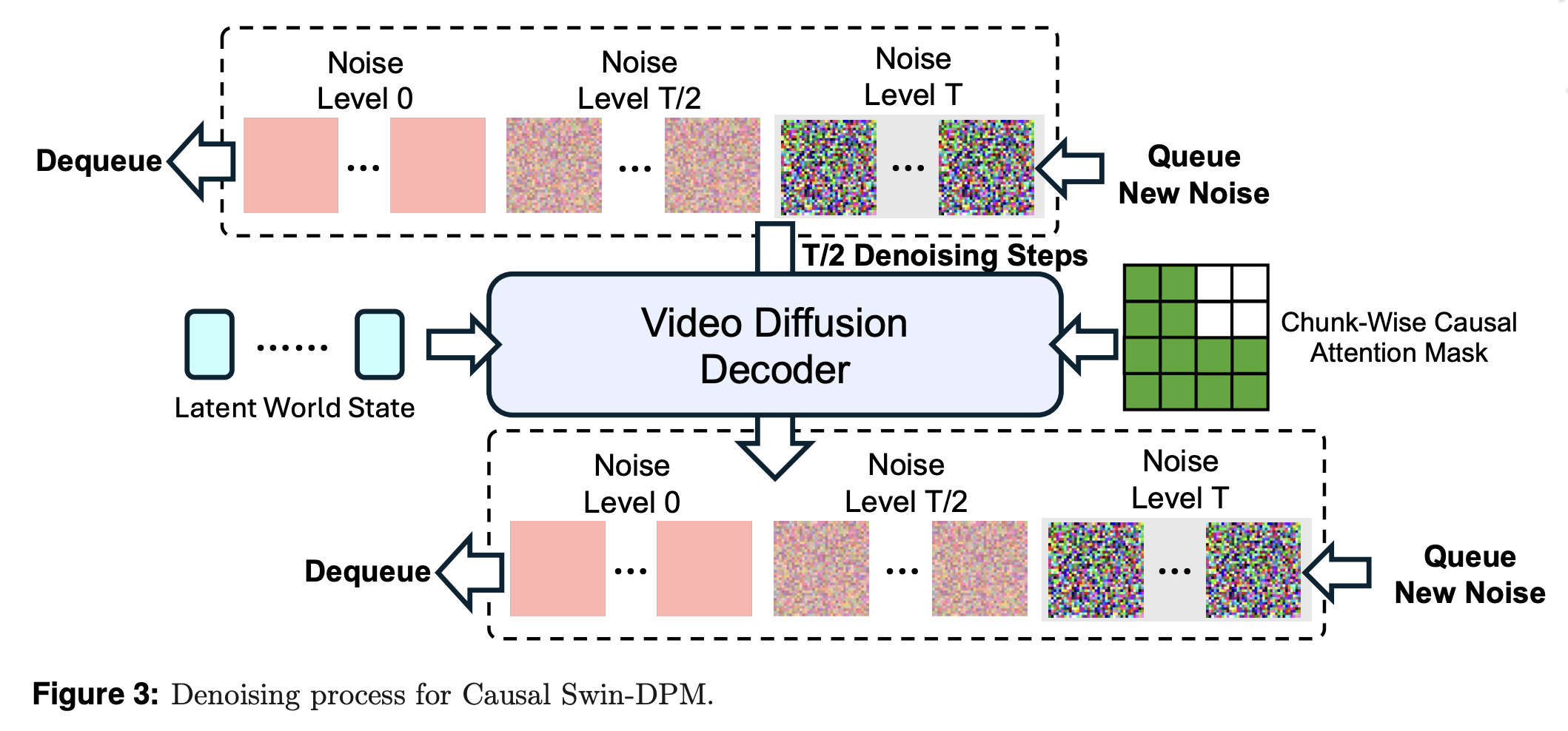
If you condition only the final frame of a single-shot video model, it will lead to rapid degradation in quality and local discontinuities. PAN has a solution for this problem with Causal Swin DPM. This adds chunk-wise causal attention to the Shift Window Denoising Process Model.
Decoders work with a sliding window which holds video frames of different sound levels. The decoder moves one piece from noisy frames to cleaner ones and leaves the window. At the opposite end, a new chunk is introduced. This ensures the chunks can focus on the previous one and ignore future events. It keeps the transitions between pieces smooth, and helps reduce error accumulation on long-term horizons.
PAN adds noise control to the condition frame instead of using an absolutely sharp frame. The model is encouraged to concentrate more on objects, layouts and stable structure. This way incidental pixels are suppressed and do not affect dynamics.
Build a data stack for training
PAN training is done in two phases. The first step is to adapt Wan2.1T2V14B for the Causal Swin DPM. They then train the decoder using BFloat16, AdamW, a Cosine Schedule, Gradient Clipping, FlashAttention3 kernels and FlexAttention.
The second phase integrates the Qwen2.5VL7B Instruct frozen backbone and the video decoder in order to achieve the GLP goal. The model of vision language remains frozen. Model learns the embeddings of queries and decoders so that predicted latents are consistent with reconstructed video. To handle the long sequences, this joint training uses Ulysses-style attention sharding and sequence parallelism. Even though there are 5 training epochs in the schedule, an early stop ends training once validation converges.
The training data is derived from publicly available video clips that show everyday situations, such as human-object interactions, the natural environment, and scenarios involving multiple agents. Shot boundary detection is used to segment long form videos into clips. A filtering pipeline is used to eliminate static or dynamic videos, poor aesthetics, text overlays that cover the screen, excessively heavy texts, and screens recordings. It uses rule-based metrics, pretrained detectors, a VLM custom filter, and pretrained detectors. The research team then captions clips using dense, time-based descriptions that highlight motion and causal events.
Plan, set benchmarks and measure action.
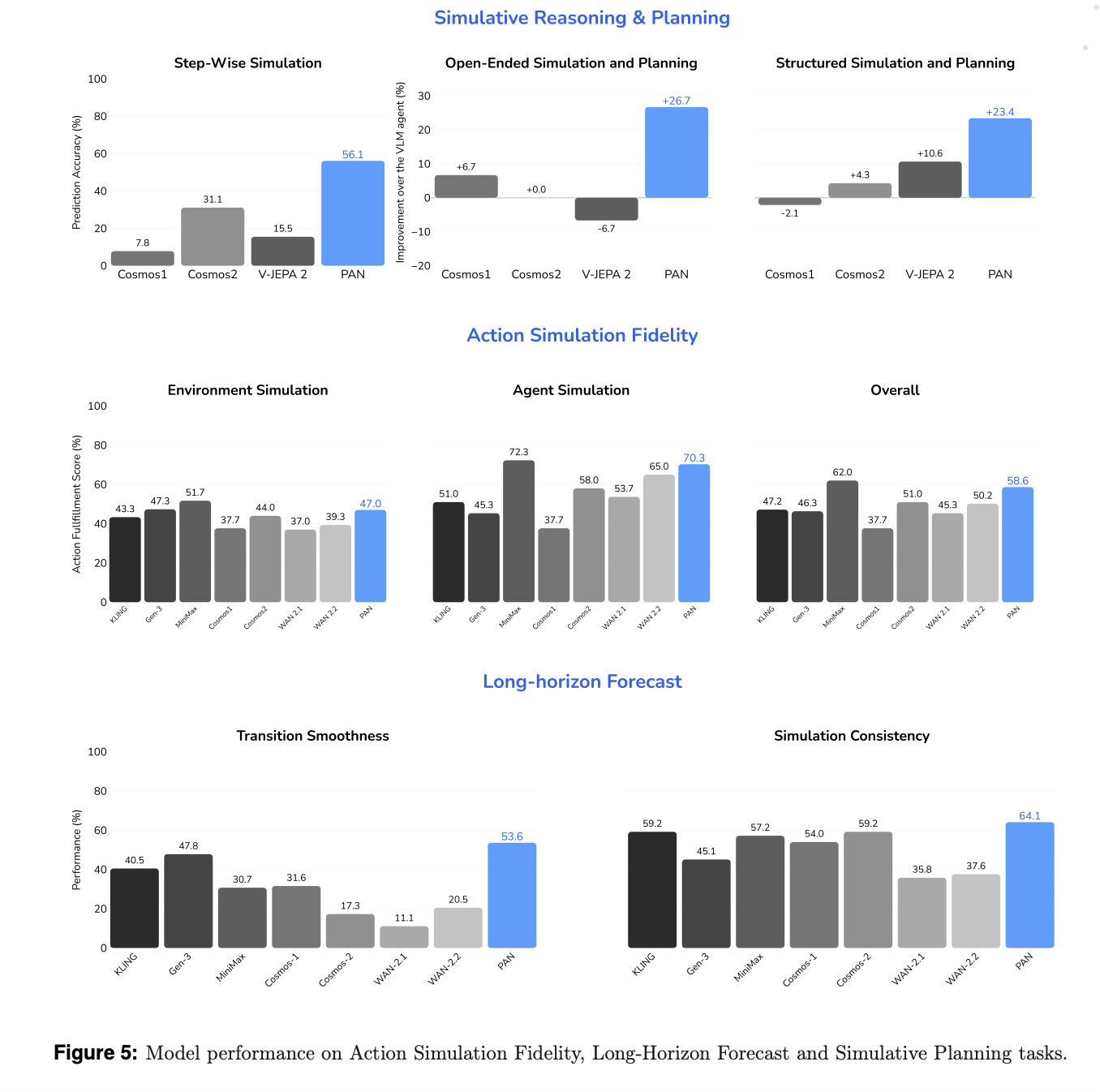
Research team assesses model on three dimensions: action simulation fidelity (action simulation accuracy), long-horizon forecasting, and reasoning and planning simulatively. They compare the results with both commercial world models and video generators that are open source. The baselines include WAN 2.1, 2.2, Cosmos 1, 2, V JEPA 2 and commercial systems like KLING MiniMax Hailuo and Gen 3.
A VLM-based judge evaluates the model’s ability to execute language specified actions, while still maintaining a stable backdrop. PAN scores 58.6% overall, with 70.3% accuracy for agent simulations and 47.5% on the environment. This model is the most accurate amongst open-source models, and it surpasses all commercial baselines.
The research team uses Simulation Consistency and Transition Smoothness to forecast long-horizons. The Transition Smoothness metric uses optical flow acceleration in order to measure how fluid motion is between action boundaries. Simulation Consistency monitors the degradation in long sequences using metrics inspired from WorldScore. PAN scored 53.6% for Transition Smoothness, and 64.1% for Simulation Consistency, and exceeded all baselines including MiniMax and KLING.
PAN can be used to simulate reasoning and plan inside of an OpenAI o3-based agent loop. PAN’s accuracy in simulation is 56.1%, which is best of all open source models.
Key Takwaways
- PAN uses the Generative Latent Prediction (GLP) architecture. It combines Qwen2.5 VL-7B as a latent dynamics core with Wan2.1 T2V-14B for video diffusion to unify reasoning about latent worlds and video generation.
- This DPM system uses the Causal Swin mechanism, which is a sliding frame, chunk by chunk causal denoising technique that works on previously noised chunks. The resultant video can be rolled out with longer horizons while reducing temporal drift.
- PAN training is done in two phases: First, the Wan2.1 encoder adapts to the Causal Swin DPM, using the 960 NVIDIA N200 GPUs. This objective focuses on flow matching. Next, the GLP stack, with its frozen Qwen2.5VL and the learned query embeddings combined with decoder, trains the GLP.
- This training corpus is composed of video pairs of action from different domains that have been processed using segmentation, filters, and dense time recaptioning. PAN can now learn long-range dynamics conditioned by action instead of short isolated clips.
- PAN achieved state-of-the art results in open source on action simulation fidelity and long horizon planning. Scores such as 70.3% for agent simulation, 48.7% for environment simulation, 53.6 % transition smoothness and 64.1% consistency were reported, all while being competitive with commercial systems.
Comparative Table
| Measurement | PAN | Cosmos video2world WFM | Wan2.1 T2V 14B | V JEPA |
|---|---|---|---|---|
| Organization | MBZUAI Institute of Foundation Models | NVIDIA Research | Wan AI and Open Laboratory | Meta AI |
| The primary role | World model with long-horizon interactive simulation and natural language actions | Physical AI platform with world-generation video for navigation and control | Create and edit content with a high-quality text to video or image to video converter. | Video model that can be used to self-supervise understanding, planning and prediction tasks |
| World model framing | The explicit GLP model, the latent state, next observation, and action are defined. This focuses on simulation and planning. | The world foundation is a model for generating future video universes from previous video and command prompts. It’s aimed at Physical Artificial Intelligence, Robotics, Driving, Navigation. | Documents are not persistent world states, but rather a video-generation model. | Joint embedding predict architecture for video focuses on latent rather than explicit generation supervision in observation spaces |
| Core Architecture | The GLP stack is a vision encoder based on Qwen2.5 VL7B. A latent dynamic backbone is based on LLM. Video decoding with Causal-Swing DPM. | A family of diffusion-based, autoregressive, world models. Includes video2world generation and diffusion decoder/upsampler. | The T2V spatial-temporal variational autoencoder model with 14 billion parameters supports multiple generative and resolution tasks. | JEPA-style encoder and predictor architecture which matches the latent representations in consecutive video observations |
| Backbone with latent space | Latent multimodal space using Qwen2.5 VL7B for encoding and auto-regressive predictions under actions. | Model variants vary in terms of the video2world token-based model, with optional text prompt conditioning as well as diffusion decoders for refinement. | VaE latent space plus diffusion transformer, mainly driven by text or images prompts. No explicit interface for agent action sequence. | It is not generative loss that affects the latent space but rather a loss of representation space predicted by the self-supervised video encoder. |
| Input or Action | The model decodes and predicts future latent states based on the action history and natural language dialogues. | For navigation and other downstream tasks, such as autonomous driving and humanoid controls, the control input can be a text prompt or a camera pose. | World model controls are not described explicitly as multi-step agent interfaces, but instead use text inputs and image inputs to control content. | It is used as a visual display and predictor in larger planners or agents. |
| Long horizon design | Causal Swin DPM sliding windows diffusion, chunkwise causal attention, conditioning of slightly noised final frame to maintain stable long-horizon rollouts and reduce drift | The Video2world Model generates the future video given a past prompt and window. It supports navigation, long sequences and support for long videos. However, it does not mention a Causal-Swing DPM type mechanism. | The Wan Bench is used to evaluate the stability of long-horizons, but it does not have an explicit world state mechanism. | It is not the generative video with diffusion windows that provides long temporal reasoning, but rather predictive latent modelling and self-supervised learning. |
| Training data focus | Video action pairs at large scales across physical and embodied realms with filtering, segmentation and dense time recaptioning to capture action-conditioned dynamics | Mixed proprietary and public Internet video mix focusing on Physical AI categories like driving, manipulations, human activities, navigation, and nature dynamics. With a dedicated curation pipe. | Wan Bench prompts for evaluation of large open domain videos and images, but not specific to agent environments. | The V JEPA 2 Paper provides details on the use of large-scale unlabelled videos for representation learning and predictive analysis. |
PAN represents an important milestone because it validates the PAN stack using well-defined benchmarks such as long-horizon forecasting and action simulation. Researchers have documented their training and assessment pipeline, reproducible metrics, and released the model within an open world modeling framework, rather than as a video demo. PAN shows that a diffusion video decoder and vision language backbone can be used to create a world model, rather than a generative tool.
Take a look at the Paper, Technical details You can also find out more about the following: Project. Check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! What? now you can join us on telegram as well.
Max is a Silicon Valley-based AI analyst who shapes the future technology. Max teaches robots at Brainvyne and combats spam through ComplyEmail. He uses AI to transform complex technology advancements every day into understandable, clear insights.