


In artificial intelligence, web automation agents are gaining in popularity due to the fact that they can perform actions similar to those of a human in digital environments. They interact with web sites via Graphical User Interfaces, mimicking behaviors like clicking, typing and moving across pages. This eliminates the need to use dedicated Application Programming Interfaces. APIs are not always available in most web applications or may be limited. They can instead operate globally across different web domains. This makes them a flexible tool for various tasks. These agents can now not only understand web content, but also plan and reason with greater sophistication. Their abilities are growing, and so is the need to assess them for more than simple browsing. Modern agents are capable of much more than the benchmarks of early models.
The web agent’s ability to perform mundane digital tasks that require memory and multiple steps is still not sufficiently measured. Cognitive effort is required for many of the tasks humans do on websites. For example, retrieving data on different pages, performing calculation based on past inputs, and applying complex rules. They aren’t just navigational challenges, but also test your memory, logic and planning. The majority of benchmarks, however, focus on scenarios that are simplified and don’t reflect digital chores which people tend to prefer to avoid. The limitations of these benchmarks are also more evident as the agents perform better. Inconsistencies or ambiguity in the task instructions can start to affect evaluations. Due to unclear task definitions, agents who produce reasonable answers but with slight differences are penalized in the wrong way. These flaws can make it hard to differentiate between real model limitations and shortcomings in benchmarks.
WebArena was used as a benchmark to measure web agent performance. WebArena has been widely adopted due to the reproducibility of its simulations and their ability to mimic real-world sites, such as Reddit and GitLab. The over 800 tests were meant to measure an agent’s capability to achieve web-based tasks within the environments. The tasks were mainly focused on browsing, and they did not challenge the more experienced agents. Mind2Web and GAIA are other benchmarks that explore real web tasks. They also look at platform-specific environments, like ServiceNow. But each comes with its own set of trade-offs. Other benchmarks lacked interactive features, some did not allow reproducibility and others were too restricted in their scope. The limitations of the agent measurement system created an inability to measure progress when it comes to areas like complex decision-making and long-term memory.
Researchers at the University of Tokyo have introduced WebChoreArena. The expanded framework is based on the WebArena structure, but increases complexity and difficulty of tasks. WebChoreArena has 532 newly-curated tasks distributed on the four websites simulated. They are more challenging, reflecting real-life scenarios in which agents have to engage in data aggregation and memory recall tasks, as well as multi-step reasoning. The benchmark has been designed to be reproducible and standard, which allows fair comparisons of agents, and avoids the ambiguity found with earlier tools. Inclusion of different task types and input modes helps to simulate realistic web use and evaluate agents at a practical and challenging level.
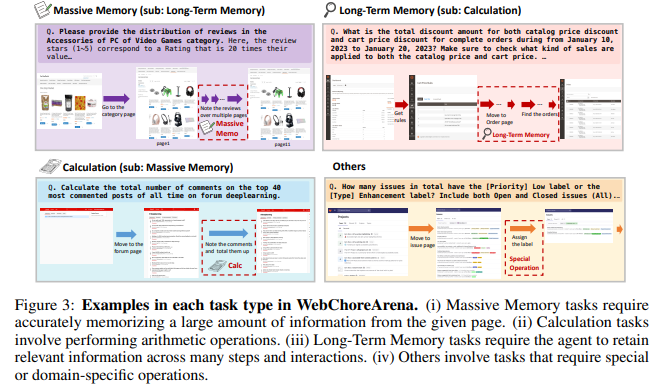
WebChoreArena classifies its tasks in four major categories. Massive Memory is a category of 172 tasks, which require agents to memorize and store large quantities of information. For example, compiling the names of all customers associated with transactions that are high in value. The 132 tasks in the Calculation category involve math operations, such as identifying months with highest expenditures based on several data points. These 127 tasks test your agent’s memory and ability to integrate information on different sites, for example retrieving price rules from a site and applying it elsewhere. An additional 65 tasks are categorized as ‘Others’, including operations such as assigning labels in GitLab that do not fit traditional task formats. Every task has a specific input method. There are 451 tasks that can be completed with any observation. 69 only require textual input. And 12 solely rely on image input.

Researchers evaluated benchmarks using GPT-4o and Claude 3.7 Sonnet. They also used Gemini 2.5 Pro. They were evaluated with the help of two web agents that are advanced, AgentOccam & BrowserGym. WebChoreArena was found to be more difficult than previous benchmarks. GPT-4o had 42.8% accuracy in WebArena but only managed 6.8% with WebChoreArena. Claude 3.7 Sonnet & Gemini 2.50 Pro were better performers, Gemini reaching a top accuracy of 44.9%. Even though it was the highest performing agent, the results still revealed significant shortcomings when tackling the more complicated tasks in WebChoreArena. This benchmark was also more sensitive to performance differences, which makes it an excellent tool for benchmarking web agent technology.
The following are some of the key findings from this research:
- WebChoreArena contains 532 tasks including: 117 Massive memory, 130 Calculation, 128 Long-Term Memory and 65 Other.
- Reddit (91), GitLab (128), GitLab (127), 65 scenarios cross-site, and Shopping (117) are the most common tasks.
- Input Types: While 451 of the tasks can be completed with just about any type of input, 12 require images and 69 textual.
- GPT-4o was only able to score 6.8% at WebChoreArena as opposed to 42.8% when using WebArena.
- Gemini 2.49 Pro received the highest rating of 44.9%. It indicates that there are currently limitations to handling complicated tasks.
- WebChoreArena has a greater performance gradient among models than WebArena. It is therefore more useful for benchmarking.
- To ensure reproducibility and diversity, 117 templates of tasks were created. Each template was used approximately 4.5 times.
- Its rigorous construction required more than 300 hours for annotation and refinement.
- To assess accuracy, evaluations use string comparisons, URL matches, and HTML structures.
This research brings to light the gap between the general level of browsing and higher order cognitive skills required for tasks on the web. WebChoreArena is a detailed and robust benchmark that pushes web agents to rely more on logic, reasoning and memory. The WebChoreArena replaces ambiguity by standardization and the tasks are designed to mimic digital chores that agents will need to learn in order to automate real-world processes.
Click here to find out more Paper, GitHub Page You can also find out more about the following: Project Page. The researchers are the sole credit holders for this work.
🆕 Did you Know? Marktechpost is the fastest-growing AI media platform—trusted by over 1 million monthly readers. Book a strategy call to discuss your campaign goals. Also, feel free to follow us on Twitter Join our Facebook group! 95k+ ML SubReddit Subscribe Now our Newsletter.
Asif Razzaq serves as the CEO at Marktechpost Media Inc. As an entrepreneur, Asif has a passion for harnessing Artificial Intelligence’s potential to benefit society. Marktechpost is his latest venture, a media platform that focuses on Artificial Intelligence. It is known for providing in-depth news coverage about machine learning, deep learning, and other topics. The content is technically accurate and easy to understand by an audience of all backgrounds. This platform has over 2,000,000 monthly views which shows its popularity.