


TL;DR: AgentFlow is a trainable agent framework with four modules—Planner, Executor, Verifier, Generator—coordinated by an explicit memory and toolset. The planner is optimised The loop A new method of policy formulation is available. Flow-GRPOThe, which applies KL regularization with group-normalized benefits and broadcasts an outcome-level reward at every turn. On ten benchmarks a tuned 7B with Flow GRPO reported +14.9% for search (search), +14.0% for agency (agenttic), +14.5% for math (math), plus +4.1% in science (science).
What is AgentFlow?
AgentFlow formalizes tool-integrated multi-turn reasoning into a Markov Decision Process. The MDP is applied at each step. Plan The sub-goal is selected and the tool chosen, plus the context. Executor The tool is called the Verifier If you continue, the signal will indicate whether you should. Generator It emits a final answer at the end. An evolving, structured memory stores states, verification signals, and tool calls. This constrains context growth, while making the trajectories auditable. The planner can only be trained. Other modules may have fixed engines.
Public implementation is based on a modular kit (e.g. base_generator, python_coder, google_search, wikipedia_search, web_searchThe repository is MIT-licensed. This repository has an MIT license.

Training Method: Flow-GRPO
The Flow-GRPO is a group-based policy optimization based on flow. Converts sparse reward, long-horizon optimization into tractable one-turn updates
- Reward broadcast for final outcome: A single and verifiable signal of trajectory level (LLM as judge correctness) will be assigned. Every TurnAchieving global success requires aligning local and regional planning.
- The clipped target at token level: To prevent drift, importance-weighted rates are calculated per token. A PPO clipping style and KL penalties to the reference policy is used.
- Group-normalized advantages: Stabilizing updates through variance reduction in groups of policy rollouts.
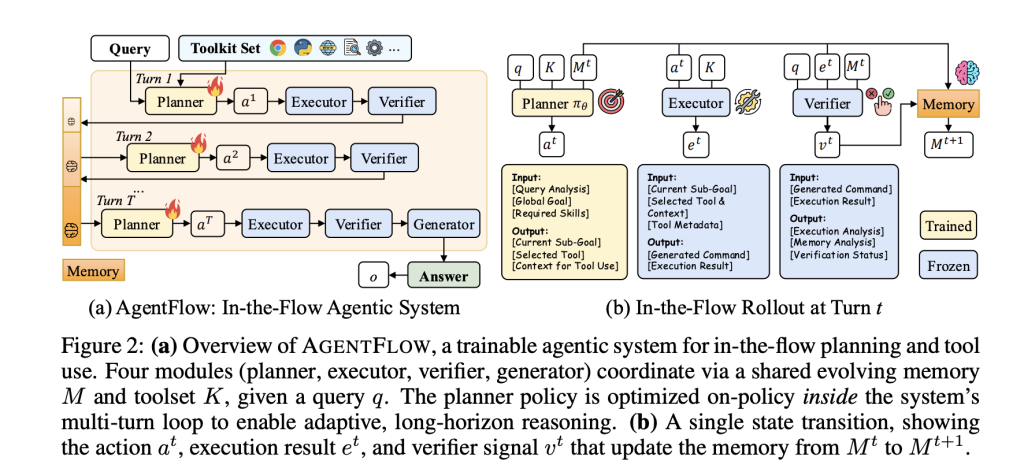
Understand the benchmarks and results
Benchmarks. The research team evaluated four tasks types: Knowledge-intensive Search (Bamboogle 2, 2Wiki HotpotQA Musique), Agentic Reasoning (GAIA textual Split), Math (AIME-24 AMC 23 Game of 24) and Science (GPQA MedQA). GAIA, a benchmarking tool for general assistants, excludes requirements related to multimodality.
Main numbers (7B backbone after Flow-GRPO). The average gains per strong baseline: +14.9% (search), +14.0% (agentic), +14.5% (math), +4.1% (science). The team explains their 7B System GPT-4 surpasses GPT-4 The project page also reports training effects such as improved planning quality, reduced tool-calling errors (up to 50%), and increased productivity. This page reports on the training effect, such as better planning quality or reduced tool call errors (upto 28.4% On GAIA), there are positive trends in the model’s turn budget and scale.
Ablations. Online Flow-GRPO improves performance by +17.2% The performance of the planner is reduced by 12% when compared to a baseline frozen plan. −19.0% By a composite measure.
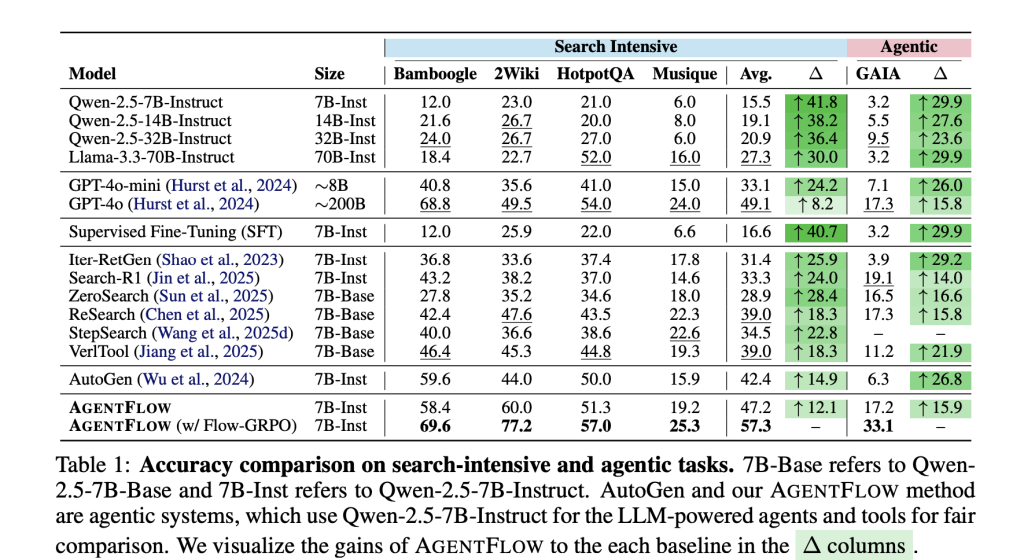
What you need to know
- Only planners can be trained in the modular agent training. AgentFlow structures an agent into Planner–Executor–Verifier–Generator with an explicit memory; only the Planner is trained in-loop.
- Flow-GRPO converts RL with a long-horizon to updates that only require ONE-TURN. The reward for each turn is a signal at the trajectory level; it uses tokens and KL regularization to update.
- Researchers reported gains in 10 benchmarks. AgentFlow, with its 7B-based backbone, reports improvements in average of +14.9% for search, +14.0% for agenttic/GAIA texts, +14.5% and +4.1% respectively, over the strong baselines. It also surpasses GPT-4o.
- The reliability of tools is improving. Research team reports reduced tool-calling error (e.g. GAIA) as well as better planning quality when using larger budgets for turns and models.
AgentFlow divides agents using tools into four modules: planner, executor and verifier. The generator is trained in-loop by Flow-GRPO. This broadcasts a single reward at the trajectory level to each turn, with token-level updates of PPO style and KL controls. The reported results for ten benchmarks showed average gains of 14.9% in search, +14.0% in textual (agenttic/GAIA), +14.5% in math and +4.1% science. In addition, the team stated that the 7B system outperformed GPT-4o. The GitHub repository includes implementation, tools and quick-starts scripts that are MIT licensed.
Click here to find out more Technical Paper, GitHub Page You can also find out more about the following: Project Page. Please feel free to browse our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! What? now you can join us on telegram as well.
Asif Razzaq, CEO of Marktechpost Media Inc. is a visionary engineer and entrepreneur who is dedicated to harnessing Artificial Intelligence’s potential for the social good. Marktechpost is his latest venture, a media platform that focuses on Artificial Intelligence. It is known for providing in-depth news coverage about machine learning, deep learning, and other topics. The content is technically accurate and easy to understand by an audience of all backgrounds. This platform has over 2,000,000 monthly views which shows its popularity.