


Many AI services are powered by large language models, which have billions of variables. Their massive size and complicated architectures, however, make inference computationally expensive. In the evolution of these models, finding the right balance between output quality and computational efficiency has become an important area of research.
LLMs are challenged by the way they handle inference. The entire model must be activated every time a new input is received, consuming a large amount of computing resources. For most tasks, this full activation of the model is not necessary as only a subset neurons are relevant to the output. Sparse activation techniques attempt to solve this problem by deactivating neurons that are not as important. These approaches tend to focus on hidden state magnitudes, ignoring weight matrixes and their critical role in spreading errors throughout the network. This leads to approximation error levels that are high and degrades the model’s performance.
Mixture-of-Experts, used in GPT-4 or Mistral models to select the experts for each input, is one example of a sparse activation technique. This method relies on training additional users to choose which experts are to be selected. Other methods, like TEAL or CATS, reduce computations by pruning neurons based on the hidden activations. However, they are still prone to improvement. The methods are often unable to balance sparsity, accuracy and precision. This is because they deactivate neurons that have minimal impact or do not retain important ones. They require model-specific tuning of thresholds, limiting their flexibility across architectures.
Microsoft researchers, Renmin University of China scientists, New York University and South China University of Technology have proposed a method to solve these problems called WINA. WINA introduces a training-free sparse activation technique that uses both hidden state magnitudes and column-wise ℓ2 norms of weight matrices to determine which neurons to activate during inference. WINA’s sparsification technique is more efficient by combining input magnitudes with weight importance. This allows it to adapt better to the different layers in the model, without the need for retraining.
WINA’s method relies on an idea that is simple, but very powerful: Neurons with strong activations are more likely than others to have a positive influence on downstream computations. WINA uses the elemental product of weight and hidden state norms to operationalize the idea. The top-K components are then selected based upon this combined metric. WINA can construct sparse networks that retain the important signals and ignore redundant activations using this strategy. This method includes a step of tensor transform that ensures the column-wise orthogonality of weight matrices. WINA achieves significant savings in computation by combining the two steps.
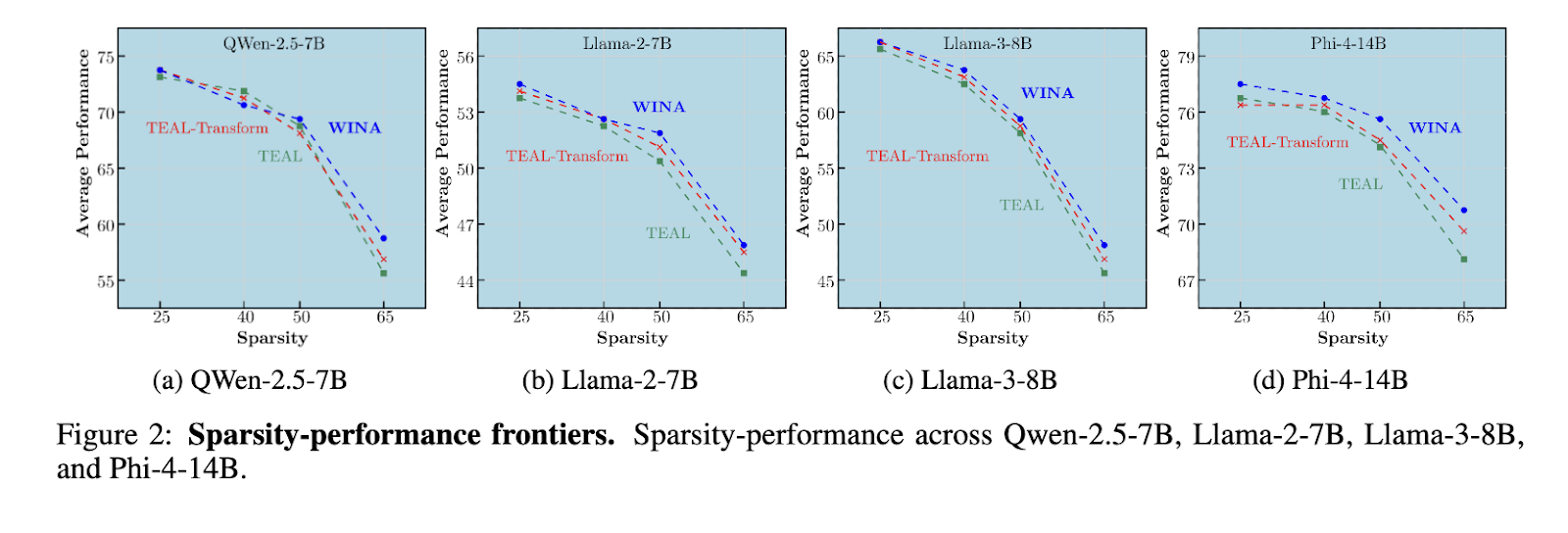
WINA has been evaluated on several large languages models including Qwen-2.5-7B LLaMA-2-7B LLaMA-3-8B Phi-4-14B across different tasks and sparsity level. WINA was superior to TEAL, CATS and all other models tested and settings of sparsity. WINA, for example, achieved a performance up to 2.94% better on Qwen-2.5-7B, at 65% Sparsity. TEAL was 1.41% worse. WINA achieved gains of 1.06% when sparsity was set to 50% and 2.41% with sparsity at 65% on LLaMA-3-8B. WINA’s performance was still better at high sparsity for tasks that require reasoning, such as GSM8K and ARC Challenge. WINA delivered the same consistent savings in computation, reducing floating point operations up to 63.7% for LLaMA-2-7B or 62.7% for Phi-4-14B.

WINA is a solution that relies on weight matrix norms and hidden state magnitudes to provide a robust sparse activation method in large language models. The approach overcomes the shortcomings of previous methods such as TEAL and results in improved accuracy, lower approximation error, and substantial computational savings. This work is an important advance in the development of more efficient LLM methods, which can be adapted to different models without additional training.
Take a look at the Paper You can also find out more about the following: GitHub Page . This research is the work of researchers. Also, feel free to follow us on Twitter Join our Facebook group! 95k+ ML SubReddit Subscribe now our Newsletter.
Sana Hassan has a passion for applying AI and technology to real world challenges. He has a passion for solving real-world problems and brings an innovative perspective at the intersection between AI and practical solutions.
