


Rewards signals guide reinforcement fine tuning. large language model Towards desirable behavior. By reinforcing the correct answers, this method improves a model’s capability to generate logical and well-structured outputs. Yet, the challenge persists in ensuring that these models also know when not to respond—particularly when faced with incomplete or misleading questions that don’t have a definite answer.
Problems arise when, following finetuning of language models, they begin to lose the ability to reject answering unclear or vague questions. In order to signal uncertainty, models often produce incorrect answers that are confidently expressed. The paper identifies this phenomenon as “hallucination tax,” This growing danger is highlighted. Models may become less likely to give correct answers when silence is more appropriate. This can be dangerous, especially in fields that need high precision and trust.
Most tools for training large models of language ignore the importance and value of refusing behavior. The frameworks used to fine tune reinforcement often reward the correct answer while penalizing any incorrect answers, and ignore situations where an acceptable response is no answer. As a result, models become overconfident because the current reward system does not adequately reinforce refusal. The paper, for example, shows that the refusal rate dropped near zero after RFT standard, which demonstrates that training does not address hallucinations properly.
Researchers at the University of Southern California created the Synthetic Non-Answerable Math dataset (SUM). SUM creates math questions that are implicitly impossible to answer by changing existing problems based on criteria like missing important information or creating logical contradictions. Researchers used DeepScaleR to create high-quality, unanswerable math questions. They then employed the o3 mini model. The synthetic dataset is designed to train models how to respond when there’s not enough information to solve a given problem.

SUM’s main technique involves mixing answerable with unanswerable questions during training. Modified questions make them ambiguous and unsolvable, while keeping the plausibility. Training prompts tell models what to say “I don’t know” for unanswerable inputs. Models can begin to use inference-time reasoning by introducing 10% of SUM data to reinforcement finetuning. They can refuse to answer questions more effectively with this structure, without affecting their performance in solving solvable problems.
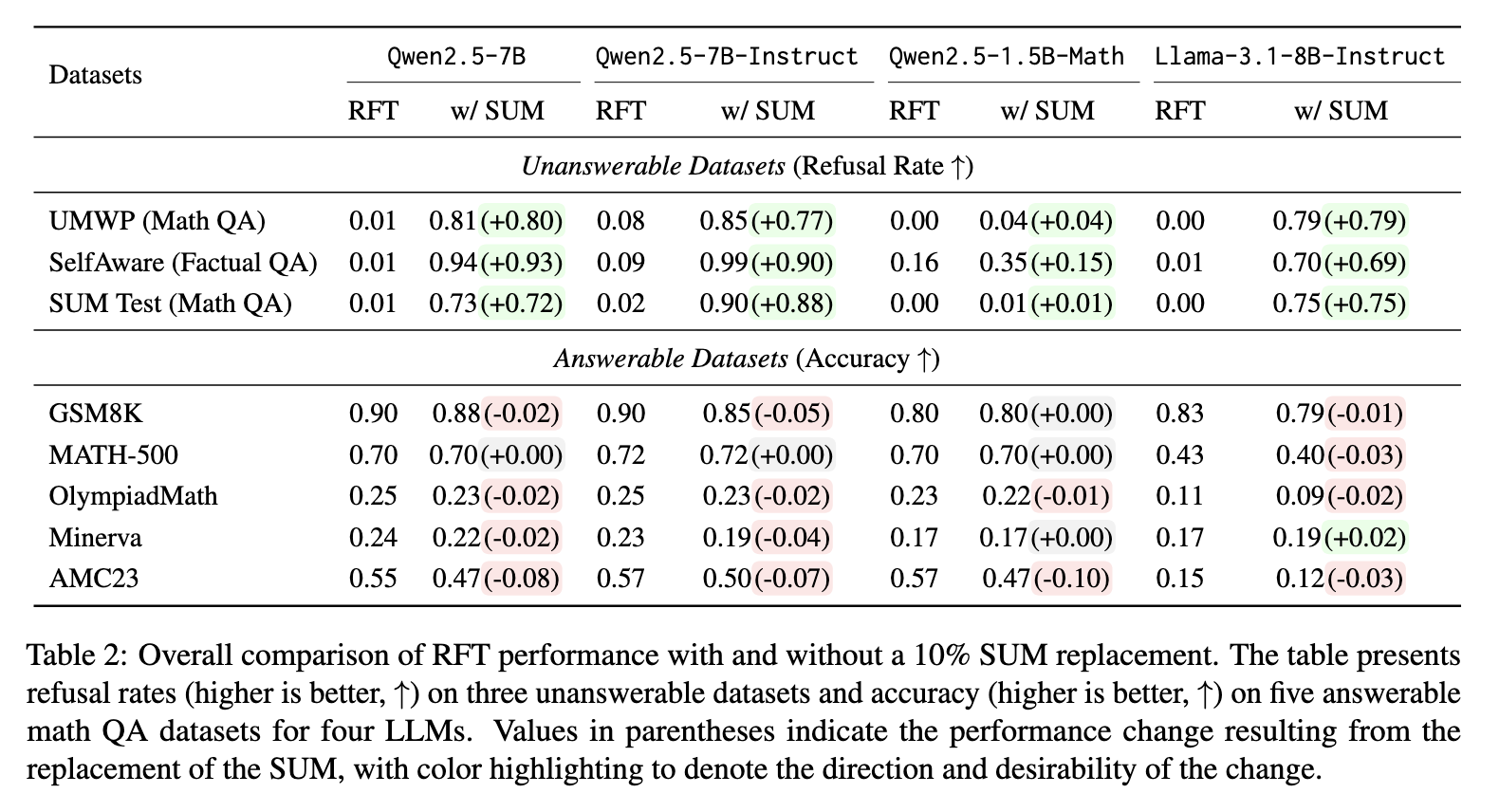
Analysis of performance shows improvements. After training the Qwen2.5-7B with SUM the model’s refusal rate increased from 0.01 up to 0.73 for the SUM benchmark, and from 0.01 up to 0.81 for the UMWP Benchmark. In the SelfAware dataset refusal accuracy increased from 0.01 to $0.94. Llama-3.1-8B-Instruct showed a similar trend, with refusal rates improving from 0.00 to 0.75 on SUM and from 0.01 to 0.79 on UMWP. Even though refusal rates improved, accuracy in answerable datasets like GSM8K, MATH 500, and GSM8K remained constant, most of the changes being between 0.00 and -0.05. This minimal decrease in performance indicates that refusing training is possible without affecting task performance.
This study highlights a clear tradeoff between increased reasoning and reliability. The finetuning of reinforcement, although powerful, can suppress careful behavior. SUM corrects for this problem by teaching the models how to identify what they can’t solve. The language models are able to identify the limits of their knowledge with only small changes in training data. This is a major step towards making AI systems more intelligent, but also honest and careful.
Take a look at the Paper You can also find out more about the following: Dataset on Hugging Face. This research is the work of researchers.
🆕 Did you know? Marktechpost is the fastest-growing AI media platform—trusted by over 1 million monthly readers. Book a strategy call to discuss your campaign goals. Also, feel free to follow us on Twitter Don’t forget about our 95k+ ML SubReddit Subscribe Now our Newsletter.
Nikhil has been an intern at Marktechpost. He has a dual integrated degree in Materials from the Indian Institute of Technology Kharagpur. Nikhil has a passion for AI/ML and is continually researching its applications to fields such as biomaterials, biomedical sciences, etc. Material Science is his background. His passion for exploring and contributing new advances comes from this.