


StepFun AI has been released by the StepFun AI Team. Step-Audio 2 MiniThe LALM is an eight-parameter speech-tospeech model that provides expressive, real-time interaction with audio. Published under the Apache 2.0 license, this open-source model achieves state-of-the-art performance across speech recognition, audio understanding, and speech conversation benchmarks—surpassing commercial systems such as GPT-4o-Audio.

The Key Features
1. Unified Audio–Text Tokenization
Step-Audio integrates ASR+LLM+TTS cascaded pipelines. Multimodal Discrete Token ModellingWhere? A single stream of modeling is shared by audio and text tokens.
It is possible to:
- The same logic can be applied to audio and text.
- On-the-fly Switching voice styles during inference.
- Consistency of semantic, prosodic or emotional output.
2. Expression and emotional awareness of the Generation
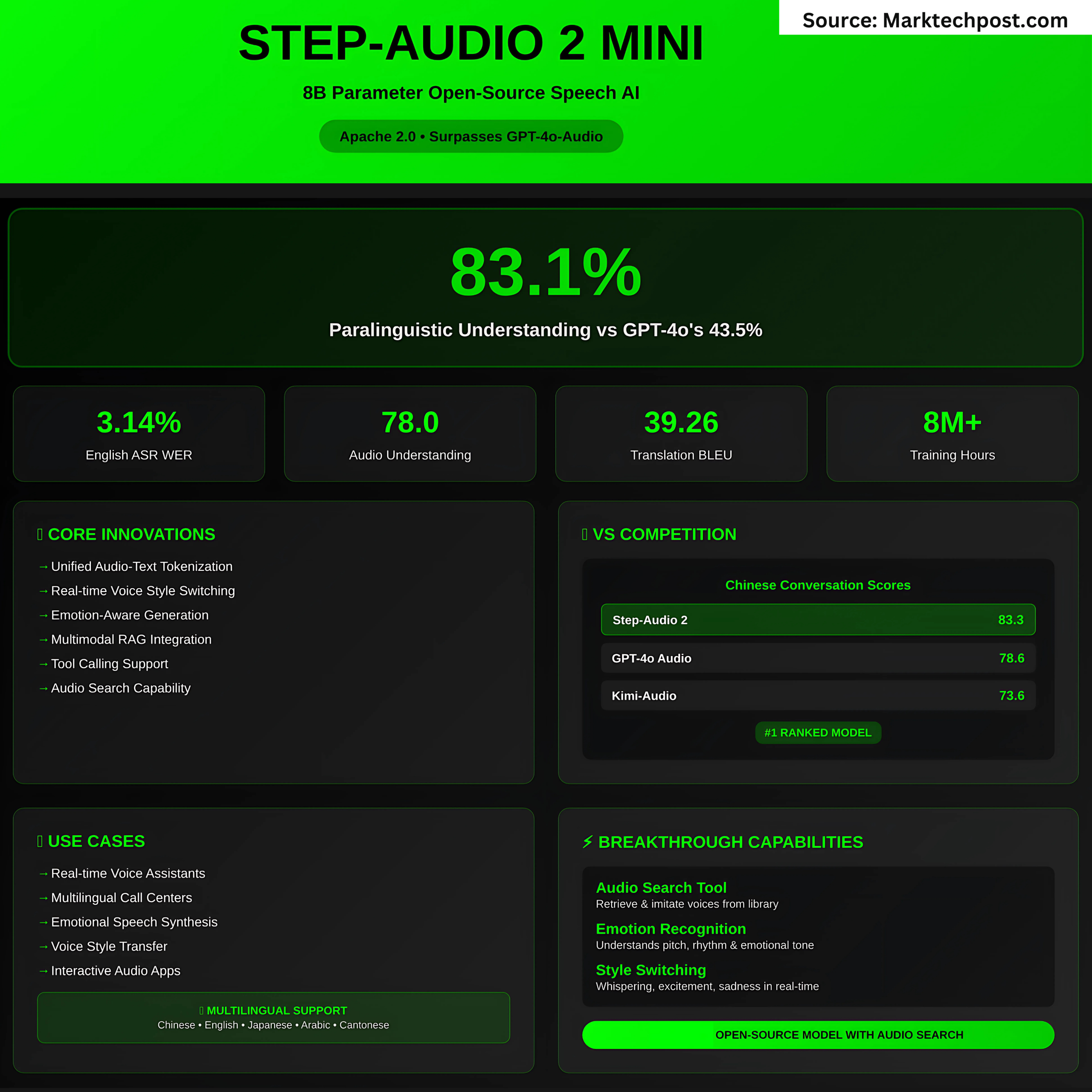
The model doesn’t just transcribe speech—it interprets Paralinguistic Features Like pitch, rhythm and emotion. It allows for conversations to have realistic emotions such as sadness or excitement. Benchmarks for StepEval-Audio-Paralinguistic Show Step-Audio 2, achieving The accuracy rate is 83.1%GPT-4o Audio (43.5%), Qwen – Omni (44.2%) are both far below the average.
3. Retrieval Enhanced Speech Generating
Step-Audio 2 incorporates multimodal RAG (Retrieval-Augmented Generation):
- Integration of Web Search Factual foundation is important.
- Audio search—a novel capability that retrieves real voices from a large library and fuses them into responses, enabling voice timbre/style imitation It’s inference-time.
4. The Multimodal Argumentation and Tool Calling
This system goes beyond just speech recognition by providing support for Invocation of the tool. Step-Audio 2 is a textual LLM that matches the benchmarks. Tool selection and accuracyThe ‘uniqueness of excellence’ in Calls for audio search are available—a capability unavailable in text-only LLMs.
Scale of Training and Data
- Text + Audio Corpus: 1.356T tokens
- Audio Hours: Real and Synthetic Hours: 8M+
- Speaker Diversity 50K voices in languages and dialects
- Pretraining Pipeline: A multi-stage program that covers ASR, TTS (speech-to-speech), and conversational synthesis with emotion labels.
Step-Audio 2 Mini can retain its strong text reasoning via Qwen2-Audio (and CosyVoice) and master fine-grained audio modelling with this large-scale training.
Performance Benchmarks


Automatic Speech Recognition
- English: Average WER is 3.14%, which is lower than GPT-4o Transcribing at an average of 4.5%.
- Chinese: CER average 3.08%, which is significantly lower than GPT-4o or Qwen-Omni.
- The same robustness across all dialects and accents.
Audio Understanding (MMAU Benchmark)
- Step-Audio 2: Average score of 78.0, beating out Audio Flamingo 3, (73.1) and Omni-R1 (77.0).
- Strengthening in The reasoning tasks based on sound and speech.
Speech Translation
- CoVoST 2, (S2TT), BLUÉ 39.26
- CVSS (S2ST: The BLEU 30,87 is ahead of the GPT-4o, (23.68).
Conversational Benchmarks (URO-Bench)
- Chinese Conversations Best overall at 83.3 (basic) You can also find out more about the following: 68.2 (pro).
- English Conversations Comparable to GPT-4o (83,9 vs. 84,5) and far superior to other open models.
The conclusion of the article is:
Step-Audio 2 Mini Multimodal Speech Intelligence is now available to developers and the research community. The combination of multimodal speech intelligence and a sophisticated user interface allows developers to create a powerful tool for research. Qwen2-AudioReasoning ability with CosyVoice tokenization pipelineAnd enhancing with Retrieval-based GroundingStepFun is a leading provider of e-games. open audio LLMs.
Take a look at the PAPER You can also find out more about the following: MODEL on HUGGING FACE. Check out our website to learn more. GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Don’t forget about our 100k+ ML SubReddit Subscribe now our Newsletter.
Asif Razzaq serves as the CEO at Marktechpost Media Inc. As an entrepreneur, Asif has a passion for harnessing Artificial Intelligence to benefit society. Marktechpost was his most recent venture. This platform, which focuses on machine learning and deep-learning news, is popular for both its technical soundness and ease of understanding by the general public. Over 2 million views per month are a testament to the platform’s popularity.