


OpenAI introduced GPT-5.1-Codex-Max. is an agentic code model that was designed to handle long software engineering projects that can span many hours and thousands of tokens. The CLI, IDE Extension, Cloud Integration and Code Review Surfaces are available in Codex today, while API access is planned for the near future.
What is GPT-5.1 Codex Max optimised for??
GPT 5.1 Codex Max was built using an improved version of OpenAI’s fundamental reasoning model. This base model was trained across various domains, including software engineering and math. On top of this, GPT-5.1-Codex-Max is trained on real world software engineering workloads such as PR creation, code review, frontend coding and Q&A.
Model is designed for frontier coding evaluations, not general conversation. GPT 5.1-Codex Max and the Codex family are recommended exclusively for agentic tasks within Codex or Codex-like environments. They should not be used to replace GPT 5.1 when it comes to general conversations.
It is also the very first Codex version to be trained in Windows environments. The training tasks include those that will make the model a more effective collaborator with the Codex CLI. This includes improved behavior when working under the Codex Sandbox and running commands.
Compaction tasks and the long run
GPT-5.1 Codex Max’s core feature is compacting. Model still operates in a single context window but is trained natively to operate across several context windows. This involves pruning the model’s interaction history and preserving important information for long-term horizons.
GPT-5.1 Codex-Max compacts the session in Codex programs when its context window is about to reach a certain size. This creates a brand new window with the same essential task state and then proceeds to execute. It repeats this process until the task is completed.
OpenAI provides internal evaluations in which GPT-5.1 Codex-Max has worked independently on a task for over 24 hours. The model fixes any failing tests, iterates its implementation and produces successful results.

Speed, reasoning effort and token efficiency
GPT-5.1-Codex-Max Uses the same reasoning-effort control as GPT-5, tuned specifically for agents. The reasoning effort controls how many tokens are used by the model before it commits to a solution.
GPT 5.1-Codex Max, with a medium reasoning effort on SWE-bench verified achieves a higher level of accuracy than GPT 5.1-Codex for the same amount of effort and 30% less tokens. OpenAI now offers a new reasoning effort called Extra High (also known as xhigh) for tasks that are not latency-sensitive. The model can think longer and come up with better solutions. The recommended mode for the majority of workloads is Medium.
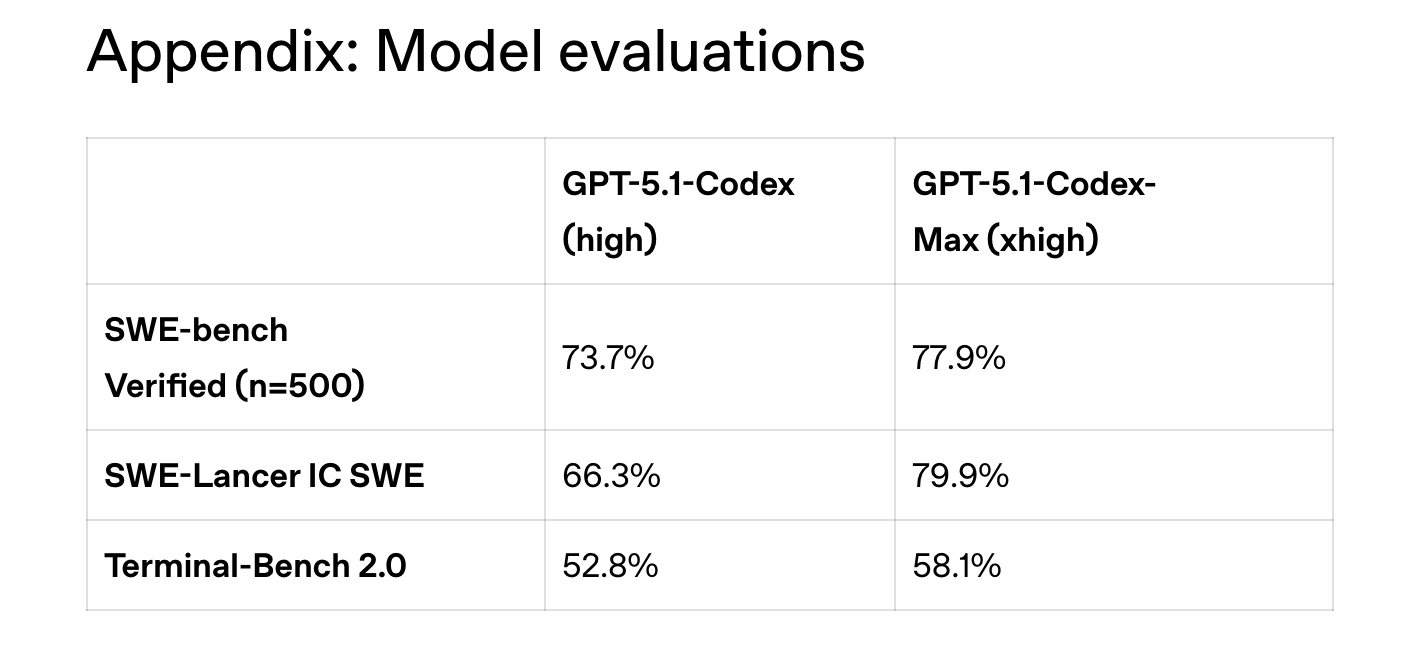
Benchmark results reflect these changes. OpenAI reported the scores for 500 SWE-bench verified issues with GPT 5.1-Codex rated at high reasoning and GPT 5.1-Codex Max rated at xhigh. 73.7% were for GPT 5.1-Codex, and 77.9%, for GPT 5.1-Codex. Scores are 66.3% on SWE Lancer IC SWE and 79.9%. The scores for Terminal-Bench 2.0 are 52.8% & 58.1%. The compaction feature is enabled in all evaluations, while Terminal-Bench uses Codex CLI within the Laude Harbor harness.
GPT-5-CodexMax generated high-quality frontend designs similar in functionality and visual appearance to GPT-5.1 Codex but with lower token costs due to the more efficient reasoning tracks.
What you need to know
- GPT 5.1 Codex Max is a frontier agentic coding model built on an updated reasoning base, further trained on real software engineering tasks such as PR creation, code review, frontend coding and Q&A, and is available today across Codex CLI, IDE, cloud and code review surfaces, with API access coming later.
- Models that support long-running tasks through compaction (where it compresses itself repeatedly to fit multiple windows) can run for up to 24 hours, and over millions of tokens.
- GPT Codex Max has the same reasoning effort controls as GPT Codex, yet at medium efforts it is faster than GPT Codex Verified on the SWE Bench Verified. At Extra High reasoning, the task becomes more difficult.
- GPT Codex Max with xhigh effort improved SWE Bench Verified (from 73.7 to 77.9%), SWE Lancer SWE (66.3 to 79.9%), and Terminal Bench 2. From 52.8 to 58.1 per cent, when compared with GPT Codex Max.
GPT-5-CodexMax makes it clear that OpenAI is investing in long-running agentic code rather than quick, one-shot edits. The model’s compaction, frontier-coding evaluations such as SWE Bench Verified, SWE Lancer IC SWE and explicit reasoning efforts controls are a great way to test the scaling of test-time computing in actual software engineering workflows and not only benchmarks. As this capability is incorporated into the production pipelines, both Preparedness Framework (PF) and Codex Sandbox (CS) will become critical. GPT-5-CodexMax is an advanced agentic coding framework that operationalises the long-horizon reasoning of developer tools.

Michal is a professional in data science with a Masters of Science degree from the University of Padova. Michal is a data scientist with a background in statistics, machine-learning, and data engineering. She excels at turning complex datasets into useful insights.