

, Trained from Scratch with Worldwide Image/Text Pairs")
Contrastive Language Image Pre-training has been a key component of modern multimodal and vision models. It enables applications like zero-shot classification, and can be used as a vision encoder in MLLMs. Meta CLIP is one of the few CLIP variations that only allows English data to be curated. It ignores a lot of non-English web content. The scaling of CLIP for multilingual data is a challenge because of two factors: (1) the inefficiency of curating non-English content at large scale, and (2) the degradation of English performance after adding multilingual information. This hinders the development of unified model optimized for English and non English tasks.
OpenAI and Meta CLIP rely heavily on English curation. And distillation-based methods introduce biases that come from outside teacher models. SigLIP 2 tries to use Google Image Search data, but its dependence on proprietary resources limits scalability. M-CLIP or mCLIP are multilingual CLIPs that use distillation to train their text encoders using low-quality images and English-only CLIP. SLIP/Lit, for example, combine language supervision and self-supervised (SSL), allowing them to achieve a balance between semantic alignment and the visual representation. These efforts have not resolved any of the fundamental issues.
Meta CLIP 2 is the result of researchers from Meta, MIT and Princeton University. It’s the first way to build CLIP models without relying external resources such as private data or machine translation. This method removes trade-offs in performance between English and non English data, by scaling up metadata, curation of data, training capacity and model. Meta CLIP 2 ensures generalizability of CLIP, its variants and OpenAI CLIP by maximizing compatibility. Its recipe also introduces three new innovations to scale globally: (a), scalable metadata for 300+ languages; (b), a curation algorithm per language for concept distribution that is balanced, and (c), an advanced training frame.

For the first, the researchers used data that was curated globally, and for the second challenge they created an international CLIP framework. This framework uses OpenAI and Meta CLIP models and their training settings. It also includes three new additions, namely a multilingual training tokenizer and scalability of training pairs. For generalizability the OpenAI CLIP ViT L/14 and Meta CLIP ViT H/14 models are used, but with some modifications to support multilingual tasks. The studies of the minimum model expressivity revealed that OpenAI ViT/L/14 struggled with the curse because it had limited capacity. However, ViT/H/14 served as an inflection, and achieved notable gains both in English and non English tasks.
Meta Clip 2 outperforms its English-only (1.0×) and non-English (1.3×) counterparts in both English and multilingual tasks when trained on ViT-H/14 with worldwide data and scaled seen pairs. In non-scaled models or smaller ones like the ViT L/14, however, this curse continues. The transition to international metadata from English is crucial. As an example, by removing the English filters from alt-texts, ImageNet accuracy drops 0.6%, underlining the importance of isolation. The initial performance of English is reduced when replacing English metadata by merged global metadata. However, this improves the multilingual capability. When evaluating zero-shot classification benchmarks and geo-localization benchmarks, it is evident that scaling the number of English-to-worldwide pairs from 13B to 29B improves performance except in GeoDE.
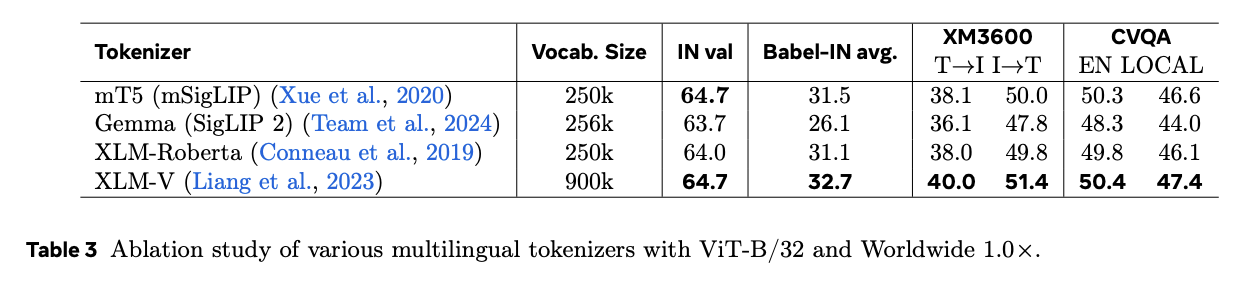
The researchers concluded by introducing Meta CLIP 2 – the first CLIP training model from scratch. This shows how scaling up metadata, curation capacity, and training capability can be a problem. “curse of multilinguality”Meta CLIP 2 (ViT-H/14) outperforms its English-only counterpart on zero shot ImageNet (80.5 % vs. 81.3 %) and excels in multilingual benchmarks such as XM3600, BabelIN, and CVQA with a single unified model. Meta CLIP 2 (ViT-H/14) outperforms its English-only counterpart on zero-shot ImageNet (80.5% → 81.3%) and excels on multilingual benchmarks such as XM3600, Babel-IN, and CVQA with a single unified model. Meta CLIP 2, by open sourcing its metadata and curation methods as well as the training code for MetaCLIP, allows the research community move away from English-centric approaches to embrace the multimodal potential of the web.
Take a look at the Paper You can also find out more about the following: GitHub Page. Please feel free to browse our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe now our Newsletter.

Sajjad is in his final year of undergraduate studies at IIT Kharagpur. Tech enthusiast Sajjad is interested in the applications of AI, with an emphasis on their impact and real-world implications. His goal is to explain complex AI concepts clearly and in an accessible way.