


How far could a language model of a sizeable mid-range go, if real innovation was moved away from the backbone and into the agent’s scaffolding and toolset? Meta researchers and Harvard University have developed the Confucius Code Agent. It is an open-source AI software engineer that uses the Confucius SDK and was designed to work with large software repositories. The system is designed to target real GitHub project, complex testing toolchains during evaluation, and reproducible benchmark results such as SWE Bench Pro or SWE Bench Verified.

Confucius SDK scaffolding around model
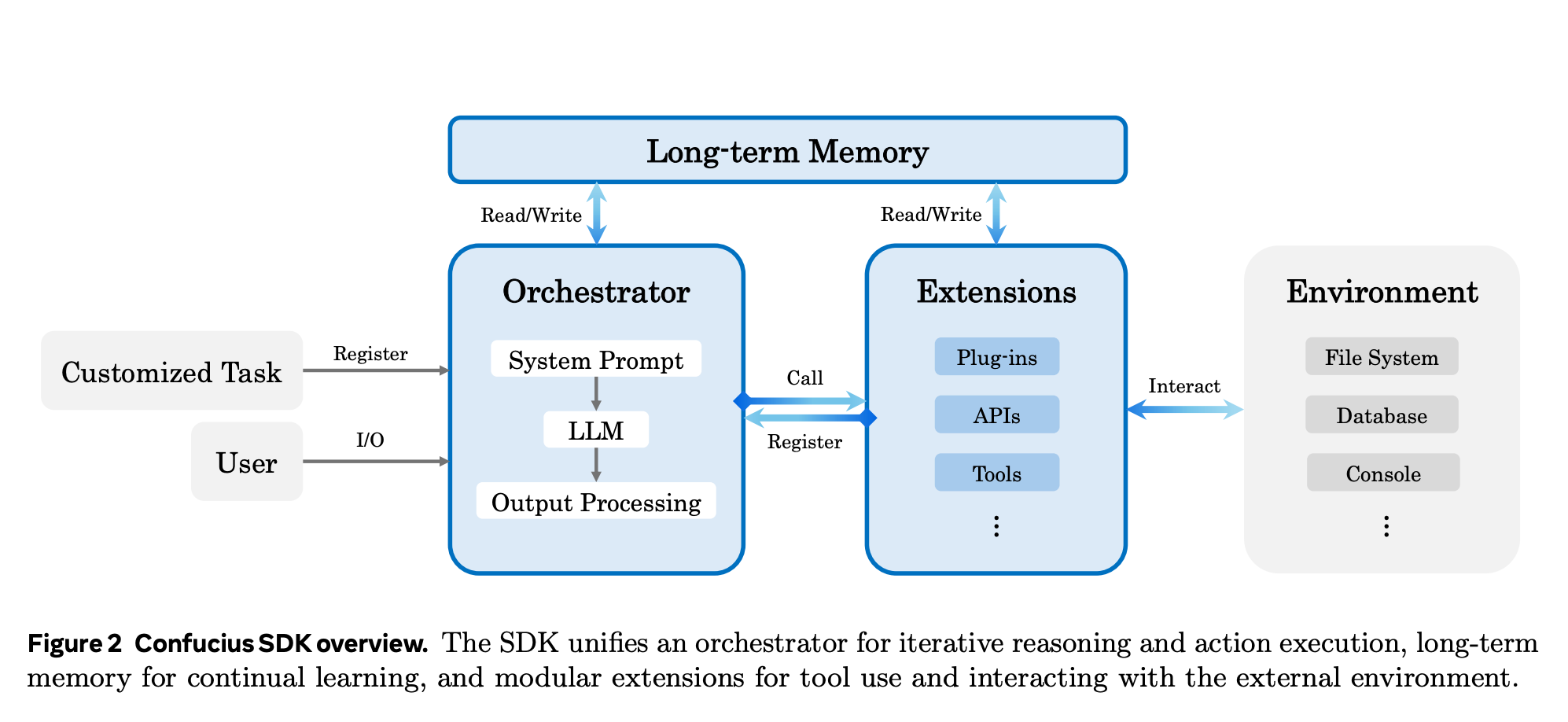
Confucius SDK, an agent-based development platform, treats scaffolding more as a design challenge than just a wrapper for a language. It’s organized around three axes. Agent Experience, User experience and Developer Experience.
Agent Experience Controls what the model can see, such as context, working memory, and tool results. Users Experience The focus is on the readable trace, code diffs, and safety for engineers. Developer Experience Focuses on the agent’s configuration, observability and debugging.
The SDK includes 3 main mechanisms: a hierarchical orchestrator, persistent notes, and an extension interface that allows tools to be added. Meta agents automate the refinement and synthesis of configurations using a “build, test,improve” loop. Confucius Code Agent (CCA) is an example of a scaffold that can be used for software engineering.
Working memory hierarchy for coding with long-horizon
SWE Bench Pro is often used to perform real-world software tasks that require dozens or even hundreds of files. Confucius SDK’s orchestrator maintains hierarchical memory that partitions the trajectory of a trajectory, summarises past steps, and retains compressed context.
The design allows prompts to remain within the model context while maintaining important artifacts like patches, error logs, and design decisions. Effective tool-based coding agents require an explicit memory structure, and not just a window that slides back to previous messages.
Note taking across sessions: a persistent note-taking system
Second, a system of note-taking is used that writes structured Markdown from the execution trace using a special agent. These notes contain task-specific strategies, repository conventions, and common failure mode. They are saved as long-term memories that can be used across sessions.
Confucius Code Agent was run twice by the research team on 151 instances of SWE Bench Pro with Claude 4.5 Sonnet. During its first execution, the agent creates new tasks and notes. The agent then reads the notes. This setting results in a drop of average turns from 64 to about 61. Token usage also drops, from 104k down to 93k. Resolve@1 increases from 53.4 to 54.4. It is clear that the notes do not only serve as logs but also act as a cross-session memory.
Use of modular extensions and tools
Confucius SDK provides tools in the form of extensions. For example, file editing, command execution and test runners. Each extension has its own state, prompt wiring and can be maintained.
Researchers study the impact of tool sophistication by ablationing 100 examples of SWE Bench Pro. Resolve@1 goes up from 42.0 to 48.6 with Claude Sonnet when you switch from a configuration lacking advanced context features, to one that includes advanced context. Claude 4.5 Sonnet reaches 44.0 with a configuration that is simple, but rich tool usage reaches 51.6. A variant in the middle reaches 51. This data shows that the choice of backbone models is not as important as how an agent sequences or selects tools.
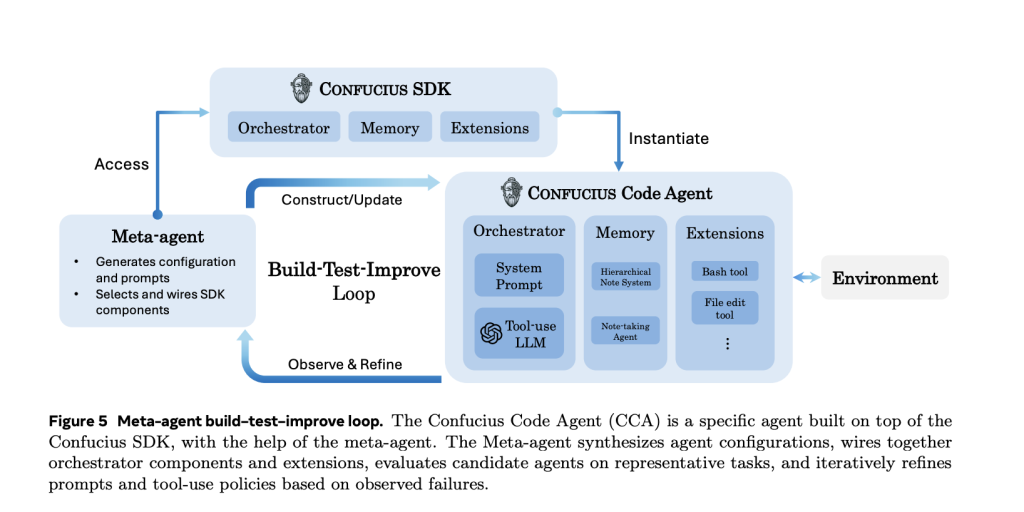
Meta agent for automatic agent design
The Confucius SDK also includes a meta-agent that, on top of all these mechanisms, takes the natural language specification for an agent, and proposes iteratively configurations, prompts, and extension sets. The candidate agent is then run on tasks and traces, metrics are inspected, and the configuration is edited in a loop of build, test and improve.
This meta-agent is used to produce the Confucius Code Agent, which the team of researchers evaluates. It does not require that it be manually tuned. This method turns some parts of the process for agent development into an LLM-guided problem.
SWE Bench Pro results and SWE Bench verified
SWE Bench Pro is used for the main evaluation. It has 731 GitHub problems that must be resolved before tests can pass. The same tool environments, repositories and evaluation harness are used by all the systems compared. Differences come down to the models and scaffolds.
The Resolve@1 score reported on SWE Bench Pro is the actual score.
- Claude 4 Sonnet, with SWE agent 42.7
- Claude 4 Sonnet, Confucius code agent 45.5
- Claude 4.5 Sonnet – SWE Agent (43.6
- Claude 4.5 Sonnet – Live Agent SWE, 45.8
- Claude 4.5 Sonnet containing Confucius code agent, 52.7
- Claude 4.5 opus with Anthropic card system, 52.0
- Claude 4.5 Opus, with Confucius code agent (54.3
The results indicate that a model of a higher tier with a middle-tier scaffold (Claude 4.5 Sonnet and Confucius Code Agent) can perform better than a model with a lower scaffold, Claude 4.5 Opus with 52.0.
Confucius Code Agent Claude 4 Sonnet reaches Resolve@1 74,6 on SWE Bench Verified. This compares to SWE Agent at 66.6 and OpenHands at 72.8. The mini SWE Agent version with Claude 4.5 Sonnet reaches a score of 70.6. It is the same as Confucius Code Agent.
For each task, the research team reports performance based on how many files were edited. Confucius Code Agent achieves 57.8 Resolution@1 for tasks that edit 1 to 2 files. For 3 to 4 file editing, it is 49.2, 5 to 6 files are 44.1 and more than 10 files reach 44.4. This shows stable behavior when changing multiple files in large codebases.
What you need to know
- The size of the model is not as important as scaffoldingConfucius code agent shows that Claude 4.5 Sonnet reaches 52,7 Resolve@1 with a strong scaffold on SWE Bench-Pro. This surpasses Claude 4.5 Opus with a weaker framework at 52,0.
- The hierarchy working memory is crucial for long-horizon codingConfucius SDK’s orchestrator manages long paths over large repositories using hierarchical work memory and context compressing, instead of relying solely on rolling histories.
- Effective cross session memory is achieved by using persistent notesReusing structured notes on 151 SWE Bench-Pro tasks using Claude 4.5 Sonnet reduces the number of turns to 61 and token usage to 93k. It also increases Resolve@1 to 54.4.
- Success rates are affected by the tool’s configurationOn a subset of 100 tasks from SWE-Bench Pro, moving from simple tool handling to more complex tool handling using Claude 4.5 Sonnet increased Resolve@1 by 44.0 points to 51.6. This indicates that the learned routing and recovery strategy is a significant performance lever.
- Meta agent is a tool that automates design, tuning and optimization of agent.The production Confucius Code Agent can be generated using this method, rather than just manual tuning.
Click here to find out more PAPER HERE. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe now our Newsletter. Wait! Are you using Telegram? now you can join us on telegram as well.
Latest Releases of ai2025.devThe platform is a focused analytics tool for 2025 that converts model launches, benchmarks and ecosystem activities into structured data you can compare and filter.
Asif Razzaq serves as the CEO at Marktechpost Media Inc. As an entrepreneur, Asif has a passion for harnessing Artificial Intelligence to benefit society. Marktechpost is his latest venture, a media platform that focuses on Artificial Intelligence. It is known for providing in-depth news coverage about machine learning, deep learning, and other topics. The content is technically accurate and easy to understand by an audience of all backgrounds. This platform has over 2,000,000 monthly views which shows its popularity.