


GPT-3 robots will soon be a reality. Researchers have been trying to train robots with the same AR models used in large language models for years. The same model which can predict the following word of a sentence should also predict the movements for robotic arms. A technical barrier has slowed this development: it is difficult to convert continuous robot movements into discrete tokens.
Researchers from Stanford University and Harvard University released a framework for analyzing the impact of climate change on global warming. Tokenization of Ordered Action (OAT). Bridge this gap

Robot Actions: A Messy Reality
Tokenization is the process of converting complex data (such as a spreadsheet) into discrete numerical values. These actions for robots are continuous signals, such as joint angles. Prior strategies have fatal flaws
- Binning: Turns every action dimension into a ‘bin.’ It is simple but creates huge sequences which slow down training and inference.
- FAST (Frequency space Action Sequence tokenization) It uses math to convert movements into coefficients of frequency. It is fast but often produces ‘undecodable’ sequences where small errors cause the robot to halt or move unpredictably.
- Learned latent tokenizers These use a learned ‘dictionary’ of movements. The model is safe, but does not have a particular order. This means that the model considers early and late tokens to be equally important.

Three Golden Rules of OAT
The research team identified 3 essential properties—desiderata—for a functional robot tokenizer:
- High Compression (P.1) For models to be efficient, token sequences should not exceed a certain length.
- Total Decodability P.2: It must perform all functions, and ensure that every sequence of tokens corresponds to an actual movement.
- Causal Ordering (P.3): Tokens should be arranged in a left to right structure, where the early tokens represent global movement and the later tokens are used for finer details.
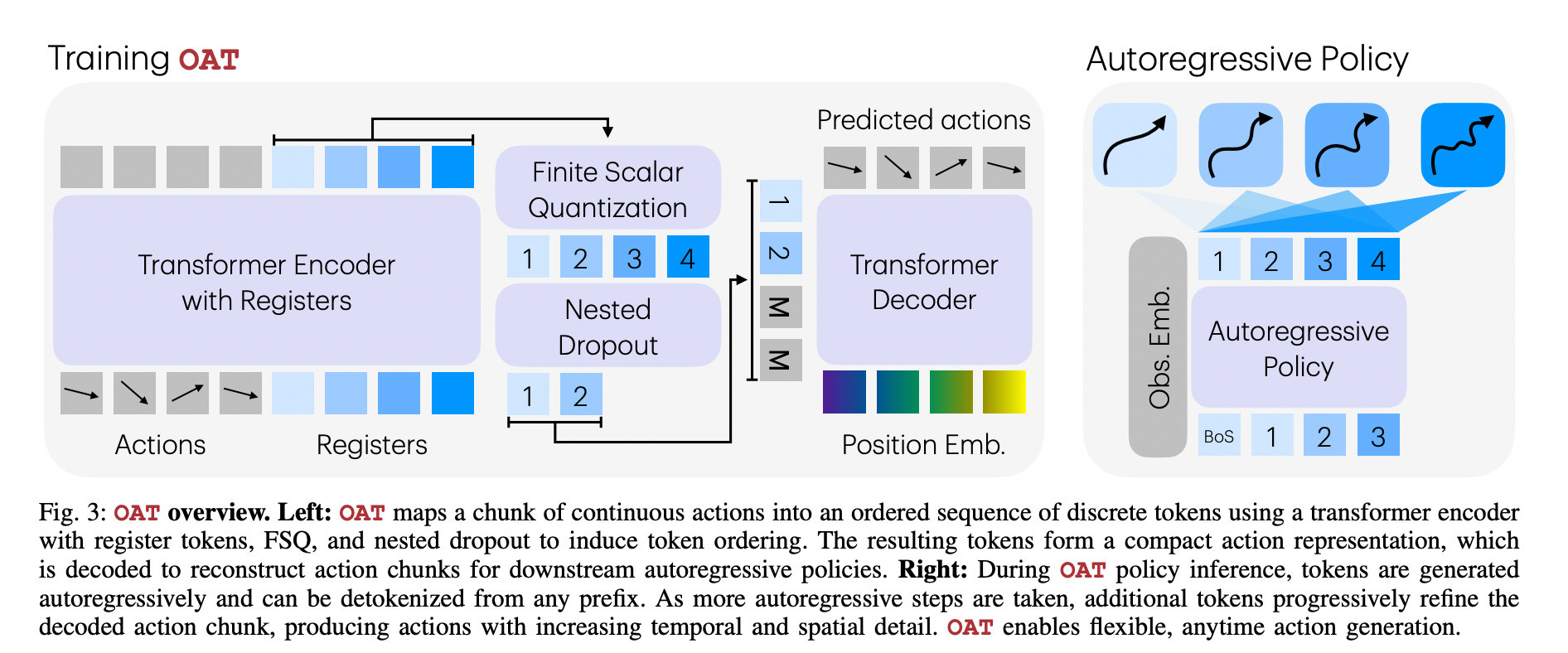
This is the secret sauce: Registers and Nested Dropouts
OAT is a Transformer Encoder. register tokens To summarize chunks of action. To force the model to learn ‘important’ things first, the research team used a innovative approach called Nested Dropout.
Benchmarks for Breaking Down Benchmarks
Researchers tested OAT on 20+ tasks across 4 benchmarks. OAT has consistently performed better than the industry standard Diffusion Policy Tokenizers that were used before.
Performance Results
| Benchmark | The OAT Success rate | Achieving DP Success | Bin Token Count | OAT Token Count |
| LIBERO | 56.3% | 36.6% | 224 | 8 |
| RoboMimic | 73.1% | 67.1% | 224 | 8 |
| MetaWorld | 24.4% | 19.3% | 128 | 8 |
| RoboCasa | 54.6% | 54.0% | 384 | 8 |
‘Anytime’ Inference: Speed vs. Precision
OAT’s most important practical advantage is Detokenization based on prefix. The tokens can be sorted by their importance so you don’t have to stop your model.
- The coarsest actions: The robot can quickly get a sense of direction by decoding only 1 or 2 tokens. This is especially useful when performing low-latency work.
- The Fine Art of Action The high precision details required for complex inserts can be obtained by generating all eight tokens.
It allows for an easy trade-off of computation cost and action faithfulness that fixed-length tokenizers previously could not provide.
What you need to know
- Tokenization and the Tokenization Gap OAT is a solution to a fundamental issue in robotics when using autoregressive model. This tokenizer achieves high compressibility, decodability of all data, and causality ordering.
- Nested Dropout for Ordered Reprsentation: By using nested dropsout, OAT can force the model to prioritise global and coarse movement patterns early on, while saving later tokens for more finely-grained refinements.
- Total Decodability and Dependability: OAT, unlike previous frequency-domain techniques like FAST ensures that the detokenizer has a complete function. This means every token sequence can generate a valid chunk of action, which prevents runtime failures.
- Flexible ‘Anytime’ Inference: This ordered structure allows robots to decode using prefixes, which can be used to perform coarse tasks with just one or even two tokens.
- Superior Performance Across Benchmarks: Autoregressive policies equipped with OAT consistently outperform diffusion-based baselines and other tokenization schemes, achieving a 52.3% aggregate success rate and superior results in real-world ‘Pick & Place’ and ‘Stack Cups’ tasks.
Take a look at the Paper, Repo You can also find out more about the following: Project Page. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! What? now you can join us on telegram as well.
Michal Sutter, a data scientist with a master’s degree in data science from the University of Padova is an expert. Michal is a data scientist with a background in machine learning, statistical analysis and data engineering.
