


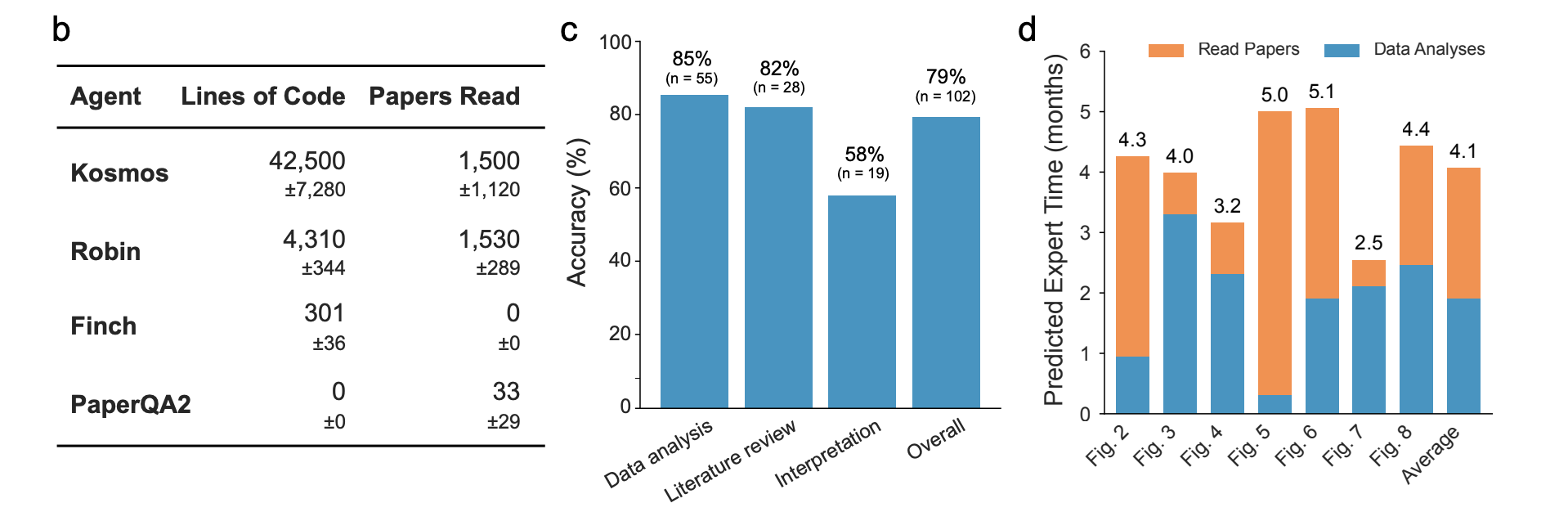
Kosmos is an automated discovery system built by Edison Scientific that can run long-term research campaigns with a specific goal. It performs an endless cycle of literature searches, data analysis and hypothesis generation. The results are then compiled into a scientific report. A typical 12-hour run includes approximately 200 agent rolls out, about 42,000 code lines, and reading about 1,500 documents.

The world model and architecture
The world model acts as the long-term memory of the system. This database is a collection of relationships, entities, results from experiments, and unanswered questions. It is constantly updated. It is structured and queryable, unlike a simple context window. This means that information about early steps can still be accessed even after thousands of tokens.
Kosmos has two agents: a data analyst and a literature researcher. The system will propose up to 10 tasks for each cycle based on the chosen research goal and current world model. For example, a differential analysis of a dataset from metabolomics or a search for pathways connecting a gene candidate to disease symptoms are examples. The agents write the code and run it on a notebook, read and retrieve papers and then return structured outputs to the world model.
The cycle repeats itself for several cycles. A separate component of synthesis traverses the model world and generates a final report, where each statement is either linked to a Jupyter Notebook cell or a passage from the primary literature. In scientific environments, this explicit provenance allows collaborators to check individual claims rather than treating the system like a blackbox.
Equivalence of accuracy and time spent on research
To evaluate the quality of reports, domain experts are asked to review 102 statements taken from three representative Kosmos Reports and classify them as either supported or refuted. Overall, 79.4 % of the statements were deemed accurate. About 85.5 percent of data analysis statements can be trusted, while literature statements and synthesis that combine evidence come in at 82.1 percent.
For estimating human equivalent efforts, the authors use 2 hours to analyze a typical trajectory of data and 15 minutes per paper. Next, they count the trajectory counts and papers for every run. A typical run would take a 40-hour work week to complete. This is equivalent to 4.1 expert month. Seven collaborating scientists rated a Kosmos 20-step run equivalent to 6.14 months worth of work by themselves on the same goal.
Representative discoveries
Kosmos has been tested with 7 different case studies, including metabolomics and materials science as well as neuroscience, statistical genetics and neurodegeneration. It reproduces human results in 3 of the cases without consulting the preprints. It proposes novel mechanisms in 4 of the cases.
Kosmos analyses metabolomics from an experiment on hypothermia in mice to make its first discovery. The system identifies the nucleotide metabolic pathway as being dominantly altered in hypothermic cerebral tissue, with reduced precursor bases and nucleosides but increased monophosphates. The system concluded that the nucleotide synthesis de novo was not as dominant in hypothermia.

Kosmos’ second discovery is based on the analysis of environmental logs taken from a solar cell manufacturing system that uses perovskite. This model recovers human results that absolute moisture during thermal annealing was the primary determinant for device efficiency. Kosmos could not access this preprint due to retrieval and model training constraints.
Kosmos’ third discovery is based on neuron-level reconstructions of several species. Distributions are fitted for neurite count, degree and length. In most datasets, the log-normal distributions of degree and synapse counts are more accurate than scaleless models. These results agree with those reported in a previous neuroscience preprint.
Four other discoveries were described as being novel. These include an analysis of Mendelian randomization that implicates superoxide dimutase as a protective factor against myocardial disease.
What you need to know
- Kosmos, an AI autonomous scientist, can run up to 12 hour per objective. It executes about 42,000 code lines and reads about 1,500 documents per run.
- Kosmos uses parallel literature and data search agents, all of which share the same central world model. This allows Kosmos to maintain a coherent reasoning over a long-horizon across approximately 200 agent deployments.
- The experts found that 79.4 per cent of the sampled statements in reports were accurate. They also noted data analysis statements and literature statements with accuracy levels above 80 per cent, but interpretation statements are less reliable.
- Kosmos runs of 20 cycles are rated as being equivalent to 6 months’ worth of research by experts.
- Kosmos reproduces and suggests novel mechanisms in seven case studies, including metabolomics and materials science. It also proposes new methods, but still requires human input for data selection and validation.
Kosmos is a good example of what happens when Edison agents with a domain-agnostic structured world model are forced to the limit of LLM tools. They deliver measurable gains for reasoning depth, reproducibility and traceability. However, they still depend on scientists in terms of data curation and objective setting. Also, the interpretation of synthesis sentences that are less reliable as data analysis statements and literature statements. Kosmos provides a good template for AI science acceleration, but it is not meant to replace researchers.
Click here to find out more Paper You can also find out more about the following: Technical details. Check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Don’t forget about our 100k+ ML SubReddit Subscribe now our Newsletter. Wait! Are you using Telegram? now you can join us on telegram as well.

Michal Sutter, a data scientist with a master’s degree in data science from the University of Padova is an expert. Michal Sutter excels in transforming large datasets to actionable insight. He has a strong foundation in machine learning, statistical analysis and data engineering.