


The semantic caching of LLM (Large Language Model), applications, optimizes the performance through storage and reuse based upon similarity in terms of content rather than exact matches. A new query will be converted into an embedded text and is compared to cached results using similarity searching. If a close match is found (above a similarity threshold), the cached response is returned instantly—skipping the expensive retrieval and generation process. If not, then the entire RAG process is executed and the response-query pair will be added to the cache.
In RAG, the cache is typically set up to only store responses for actual questions, and not each possible query. The API is able to reduce the latency of repeated questions or those that have been slightly changed. This article will look at an example that shows how caching reduces both costs and response times in LLM applications. Click here to see the FULL CODES here.
Semantic cache functions by saving and retrieving answers based on meaning rather than exact wording of queries. The semantic content of each incoming request is represented by a vector embedded. The system then performs a similarity search—often using Approximate Nearest Neighbor (ANN) techniques—to compare this embedding with those already stored in the cache.
The cached response will be returned immediately if a query and response pair is sufficiently similar (i.e. its similarity scores exceed a threshold). This avoids expensive retrieval steps or generation. If not, then the entire RAG pipeline is executed, retrieving the documents, and generating the new answer. This response will be cached for later use. See the FULL CODES here.

In a RAG application, semantic caching only stores responses for queries that have actually been processed by the system—there’s no pre-caching of all possible questions. The cache can contain the embedded query, the response and any other information that is generated by the LLM.
According to the design of the system, the cache can store either the final LLM outputs or the documents retrieved, but not both. Cache entries can be managed by policies such as time-tolive expiration (TTL), or least recently used (LRU) deletion. This ensures that recent queries or those frequently accessed remain in the cache over time. See the FULL CODES here.
Installing dependencies
Create dependencies
Import os
From getpass import Getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')OpenAI will be used in the tutorial but any LLM can also be used.
OpenAI import OpenAI
Client = OpenAI()Running repeated queries without caching
This section runs the GPT-4.1 directly 10 times to see how much time it takes without caching. This is because each call results in a complete LLM calculation and response generation. See the FULL CODES here.
It helps us establish a baseline of total cost and time before implementing semantic caching.
import time
Ask a question with def ask_gpt (query).
"Start" = "time.time()
response = client.responses.create(
model="gpt-4.1",
input=query
)
End = Time()
Output of return response[0].content[0]".text" - endQuestion "Explain the concept of semantic caching in just 2 lines."
total_time = 0
for i in range(10):
_, duration = ask_gpt(query)
total_time += duration
print(f"Run {i+1} took {duration:.2f} seconds")
print(f"nTotal time for 10 runs: {total_time:.2f} seconds")
Even though the query remains the same, every call still takes between 1–3 seconds, resulting in a total of ~22 seconds for 10 runs. This inefficiency highlights why semantic caching can be so valuable — it allows us to reuse previous responses for semantically identical queries and save both time and API cost. See the FULL CODES here.
Semantic caching for faster responses
We will enhance our previous set-up by adding semantic caching. Semantic caching allows the application to reuse answers for similar queries without having to call the GPT 4.1 API again.
Here’s how it works: each incoming query is converted into a vector embedding using the text-embedding-3-small model. The embedding captures all the meaning in the text. As soon as a new request arrives, the system calculates its cosine-similarity with embedded embeddings stored in our cache. If a match is found with a similarity score above the defined threshold (e.g., 0.85), the system instantly returns the cached response — avoiding another API call.
In the event that no similar queries exist in the cache the model creates a brand new response which can be stored with the embedding to use it again. The approach has a dramatic impact on API cost and response time over time. See the FULL CODES here.
Import numpy as an np
From numpy.linalg, import the norm
semantic_cache = []
Get embedding text with def:
emb = client.embeddings.create(model="text-embedding-3-small", input=text)
Return np.array() (emb.data[0].embedding)
Def cosine_similarity()(a,b)
return np.dot(a, b) / (norm(a) * norm(b))
def ask_gpt_with_cache(query, threshold=0.85):
query_embedding = get_embedding(query)
Compare the cache with an existing one
Semantic cache for cached_query (cached_emb), cached_resp, and cached_emb:
sim = cosine_similarity(query_embedding, cached_emb)
if sim > threshold:
print(f"🔁 Using cached response (similarity: {sim:.2f})")
return cached_resp, 0.0 # no API time
If you have any questions, please call the GPT.
"Start" = "time.time()
response = client.responses.create(
model="gpt-4.1",
input=query
)
End = Time()
Text = Response.Output[0].content[0].text
# Save in cache
semantic_cache.append((query, query_embedding, text))
Return text, start - endQuestions = [
"Explain semantic caching in simple terms.",
"What is semantic caching and how does it work?",
"How does caching work in LLMs?",
"Tell me about semantic caching for LLMs.",
"Explain semantic caching simply.",
]
total_time = 0
for q in queries:
resp, t = ask_gpt_with_cache(q)
total_time += t
print(f"⏱️ Query took {t:.2f} secondsn")
print(f"nTotal time with caching: {total_time:.2f} seconds")
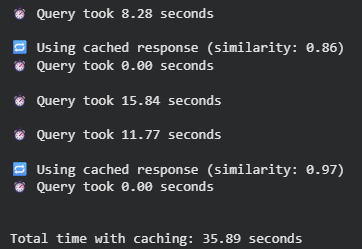
The first output query was around 8 seconds long as the cache did not exist and the model needed to create a new response. The system recognized a semantic similarity of 0.86 and reused it immediately when a question similar was asked. Some queries, like “How does caching work in LLMs?” You can also find out more about the following: “Tell me about semantic caching for LLMs,” Each response took more than 10 seconds. The second query (similarity: 0.97) was almost the same as the first, and cached responses were served instantly.
Take a look at the FULL CODES here. Check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! Are you using Telegram? now you can join us on telegram as well.

I graduated in Civil Engineering (2022), from Jamia Millia Islamia (New Delhi). I am interested in Data Science in general, but especially in Neural networks and how they can be applied in many different fields.