


The RAG system relies on dense embeddings that translate documents and questions into fixed dimensional vector space. This approach is the standard for most AI applications. However, recent research by Google DeepMind team shows that this method may not be optimal. fundamental architectural limitation It is not possible to solve the problem by simply using larger models and better training.
What is the theoretical limit of embedding dimensions?
It is important to consider the ability of embedded embeddings with fixed sizes to represent a given object. A dimension embedding D Once the database reaches a certain size, it is impossible to represent every possible combination of documents. The results of communication complexity theory and sign-rank theories support this conclusion.
- The retrieval of embeddings up to 512 pixels is around 500K documents.
- Limits for 1024 dimensions extend to approximately 4 million documents.
- There is a theoretical limit of 4096 pixels. 250 million documents.
This is a best estimate based on the data available. Free embedding OptimizationVectors can be optimized directly against the test labels. Even embeddings that are language constrained in real-world situations fail earlier.

What Problems Does LIMIT Benchmark Show?
Google DeepMind Team developed LIMIT to empirically test the limitation. LIMIT is a benchmark dataset that was designed for embedders. LIMIT is available in two versions:
- LIMIT FULL (50K Documents) Even strong embedders can collapse in this setup. Recall@100 is often affected. Minimum 20%.
- LIMIT small: The models are too small to do the job, despite their simplicity. Although performance is variable, it remains unreliable:
- Promptriever Llama3 8B: 54.3% recall@2 (4096d)
- GritLM7B 38.4% recall@2 (4096d)
- E5-Mistral 7B: 29.5% recall@2 (4096d)
- Gemini Embed: 33.7% recall@2 (3072d)
No embedder can reach full recall with only 46 documents. This shows that it is not the dataset size but rather the architecture of the embedding vectors themselves which limits the embedder.
In contrast, BM25This limitation does not affect a sparse, classical lexical model. They can capture more combinations than dense embeddings because they operate on unbounded spaces.
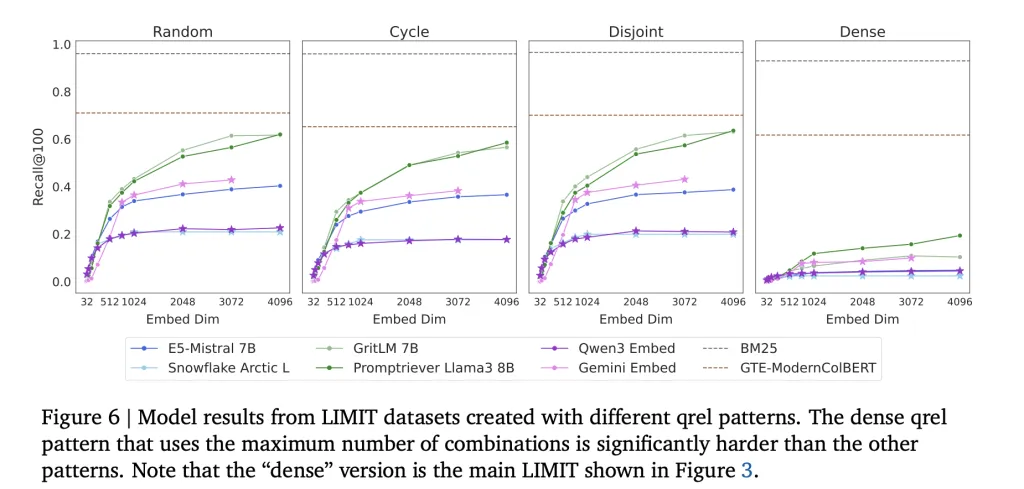
What is the significance of this for RAG
Current RAG implementations assume that embedded embeddings will scale infinitely as more data is added. Google DeepMind researchers explain why this is not true: Inherently, the size of an embedded object limits retrieval ability. It affects
- Find out more about the search engines that are available Handling millions of documents
- Agentic systems These queries are complex and require logical reasoning.
- Instruction-following retrieval tasksThe relevance of queries is determined dynamically.
Even advanced benchmarks such as MTEB do not capture these limitations, because they test a limited part/section/subset of query-document combination.
What Alternatives Exist to the Single-Vector Embeddings Method?
According to the research team, scalable retrieval requires moving beyond single vector embeddings.
- Cross-EncodersYou can achieve perfect recall of LIMIT queries by scoring directly query-document pair, at the expense of a high latency for inference.
- Multi-Vector Models (e.g., ColBERT)The retrieval is more expressive by using multiple vectors for each sequence. This improves performance when performing LIMIT tasks.
- Sparse Models (BM25, TF-IDF, neural sparse retrievers)The search engine is better at scaling in high-dimensional searches, but it lacks semantic generalization.
It is important to note that Architectural innovation is neededNot just larger embedders

The Key Takeaway:
Analysis by the research team shows that dense embeddedings are still bound to a The mathematical limitThey cannot capture all relevant combinations when corpus size exceeds limits related to embedding dimensionity. The LIMIT benchmark shows this failure in concrete terms:
- The following are some of the ways to get in touch with us. LIMIT FULL (50K documents) Recall@100 falls below 20%
- The following are some of the ways to get in touch with us. LIMIT small (46) docs: The best of the models can only recall 54% @2.
The use of classical techniques, such as BM25 and newer architectures, like cross-encoders and multi-vector retrievers, is still essential when building retrieval engines.
Click here to find out more PAPER here. Please feel free to browse our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe Now our Newsletter.
Asif Razzaq serves as the CEO at Marktechpost Media Inc. As an entrepreneur, Asif has a passion for harnessing Artificial Intelligence to benefit society. Marktechpost is his latest venture, a media platform that focuses on Artificial Intelligence. It is known for providing in-depth news coverage about machine learning, deep learning, and other topics. The content is technically accurate and easy to understand by an audience of all backgrounds. This platform has over 2,000,000 monthly views which shows its popularity.