


Can a single AI stack plan like a researcher, reason over scenes, and transfer motions across different robots—without retraining from scratch? Google DeepMind Gemini Robotics 1.5 By splitting the embodied intelligence model into two models, you can say yes. Gemini Robotics-ER 1.5 High-level embodied reason (spatial comprehension, planning, estimation of progress or success, use of tools) Gemini Robotics 1.5 for low-level visuomotor control. The system targets tasks with a long-term horizon (e.g. packing in multiple steps, sorting waste according to local laws) and introduces Motion Transfer Reuse data between heterogeneous platforms.

What exactly is The stack
- Gemini Robotics-ER 1.5 (reasoner/orchestrator): It is a multimodal planner which ingests video/images (and audio if desired), tracks progress and uses external tools to retrieve constraints (e.g. web searches or local APIs). This is available through the Gemini API Google AI Studio.
- Gemini Robotics 1.5 (VLA controller): A vision-language-action model that converts instructions and percepts into motor commands, producing explicit “think-before-act” Use traces to divide long tasks into shorter-term skills. Initial availability is restricted to selected partners.
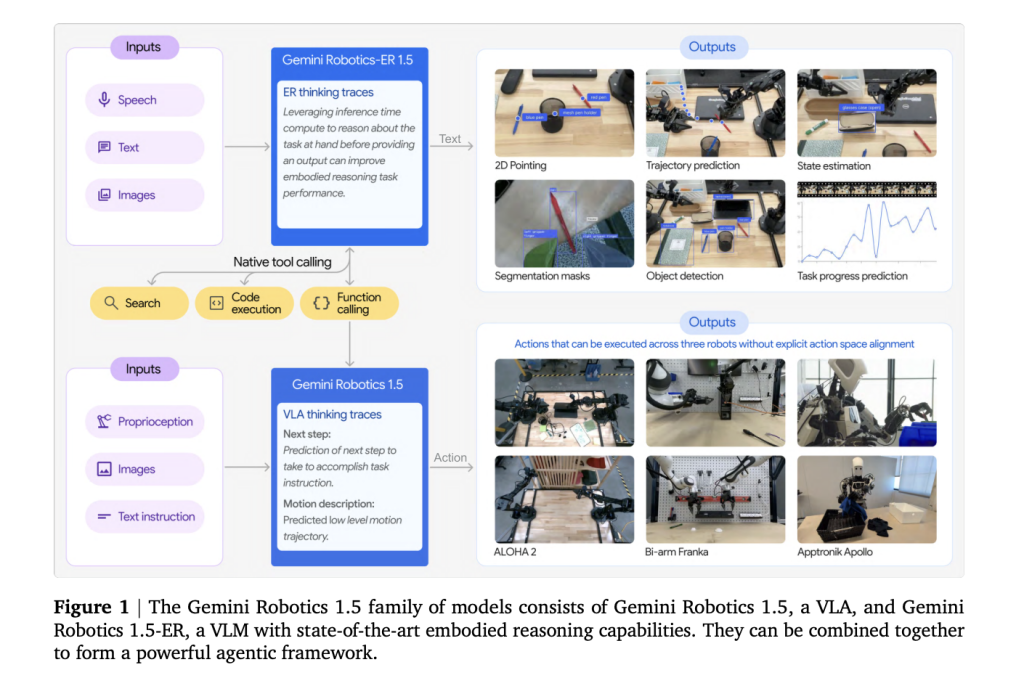
Why divide cognition from Control?
Earlier end-to-end VLAs (Vision-Language-Action) struggle to plan robustly, verify success, and generalize across embodiments. Gemini Robotics v1.5 isolates these concerns. Gemini Robotics-ER 1.5 You can also find out more about the Handles Discussion VLAs are experts in (scene reasoning and sub-goaling) while VLAs specialize in (closed-loop visuomotor control). The modularity of the system improves its interpretability (visible internal trace), recovery from errors, and reliability over a long period.
Motion Transfer across embodiments
The core contribution of the organization is Motion Transfer: training the VLA on a unified motion representation built from heterogeneous robot data—ALOHA, Franka bi-armThen, Apptronik Apollo—so skills learned on one platform can zero-shot transfer to another. It reduces data collection per robot, and the gap between simulations and reality is narrowed by using cross-embodiment previouss.
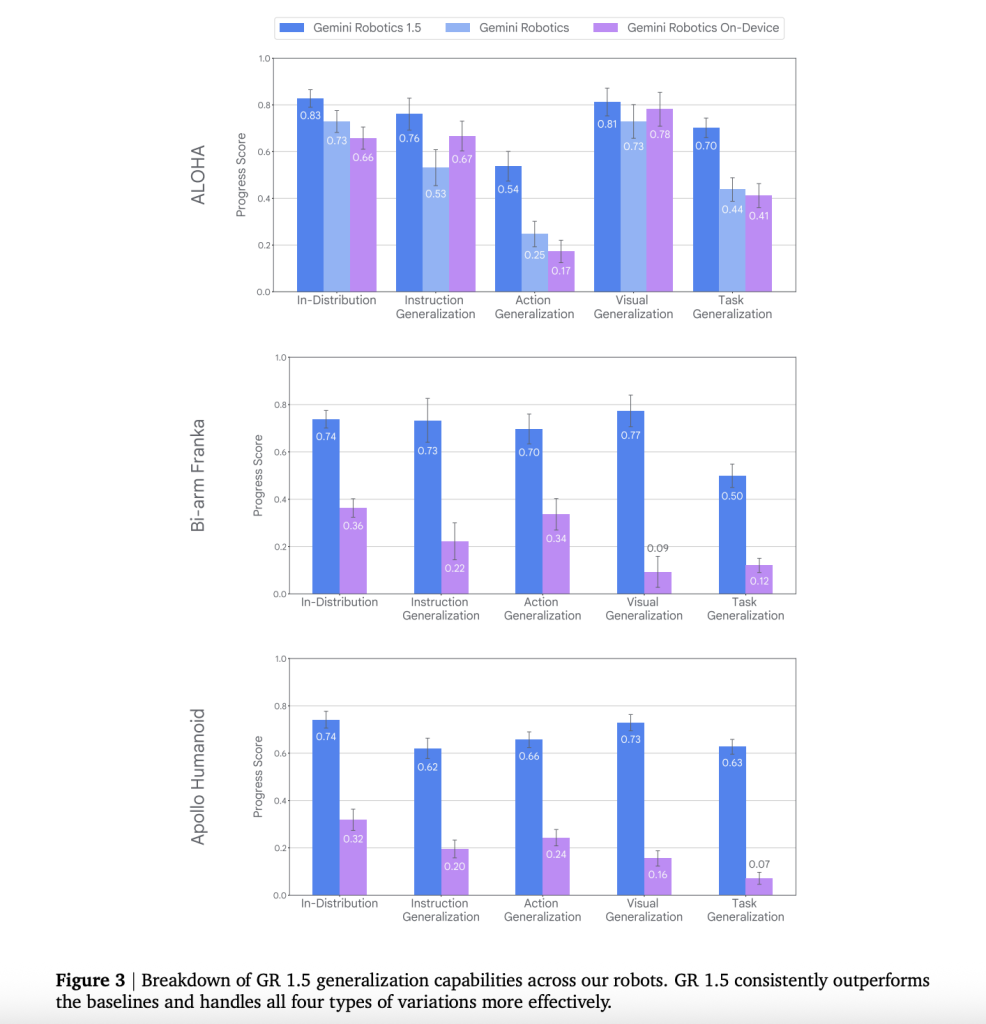
Quantitative signals
The team presented A/B controlled comparisons using real hardware. They also aligned MuJoCo scene. Includes:
- Generalization: Robotics 1.5 is superior to previous Gemini Robotics baselines for instruction following, visual generalization and task generalization.
- Zero-shot cross-robot skills: MT provides measurable results in You can also read about our progress. The following are some examples of how to get started: Success when transferring skills across embodiments (e.g., Franka→ALOHA, ALOHA→Apollo), rather than merely improving partial progress.
- “Thinking” Acting better: The ability to use VLA thinking traces improves long-term task completion, and stabilises mid-rollout plans.
- Agent gains from end-to-end: Pairing Gemini Robotics-ER 1.5 with the VLA agent substantially improves progress on multi-step tasks (e.g., desk organization, cooking-style sequences) versus a Gemini-2.5-Flash-based baseline orchestrator.
Safety evaluation
DeepMind team of researchers highlights layers of controls. These include policy-aligned planning and dialog, safety-conscious grounding (e.g. avoiding hazardous objects), lower-level limits (physical limits), as well as expanded evaluation suites. ASIMOVThe goal is to detect edge cases by using auto-red teams and ASIMOV style scenario testing. This is done to identify hallucinated objects or affordances before they are acted upon.
Competition/industry context
Gemini Robotics is now 1.5. “single-instruction” Robotics towards AgenticA set of capabilities relevant for consumer robotics and industrial robots includes multi-step autonomous with explicit tool/web use, cross-platform training, and multi-step autonomy. Early access to partners is centered on well-established robotics platforms and vendors.
What you need to know
- Two-model architecture (ER ↔ VLA): Gemini Robotics-ER 1.5 handles embodied reasoning—spatial grounding, planning, success/progress estimation, tool calls—while Robotics 1.5 is the vision-language-action executor that issues motor commands.
- “Think-before-act” control: The VLA provides explicit intermediate reasoning/traces throughout the execution process, improving both long-horizon decomposition as well as mid-task adaption.
- Motion Transfer across embodiments: A VLA checkpoint can reuse skills between heterogeneous robots, such as the bi-arm Franka (Apptronik Apollo), and allows for cross-robot execution with zero/few shot rather than per platform retraining.
- Tool-augmented planning: ER 1.5 can invoke external tools (e.g., web search) to fetch constraints, then condition plans—e.g., packing after checking local weather or applying city-specific recycling rules.
- Improvements in quantitative terms over baselines prior to the current year: The tech report documents higher instruction/action/visual/task generalization and better progress/success on real hardware and aligned simulators; results cover cross-embodiment transfers and long-horizon tasks.
- Accessibility: ER 1.5 The newest version of the Gemini API Google AI Studio with documentation, examples and preview knobs. Robotics 1.5 The (VLA), is only available to select partners. A public waiting list exists.
- Safety & evaluation posture: DeepMind emphasizes layered safety measures (policy aligned planning, safety aware grounding, and physical limits). ASIMOV upgraded Use benchmark evaluations and adversarial analysis to investigate risky behaviours and hallucinatory opportunities.
The following is a summary of the information that you will find on this page.
Gemini Robotics, version 1.5, operationalizes the clean separation of Embodied reasoning The following are some examples of how to get started: Controlling the flow of information is a good way to start.Adds Motion Transfer Gemini API allows developers to reuse data between robots and to showcase the reasoning surface to them (such as point grounding, success/progress estimation, or tool calls). For teams building real-world agents, the design reduces per-platform data burden and strengthens long-horizon reliability—while keeping safety in scope with dedicated test suites and guardrails.
Click here to find out more Paper The following are some examples of how to get started: Technical details. Please feel free to browse our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe now our Newsletter.
Asif Razzaq serves as the CEO at Marktechpost Media Inc. As an entrepreneur, Asif has a passion for harnessing Artificial Intelligence to benefit society. Marktechpost was his most recent venture. This platform, which specializes in covering machine learning and deep-learning news, is both technically solid and understandable to a broad audience. Over 2 million views per month are a testament to the platform’s popularity.