


The following is a brief introduction to the topic:
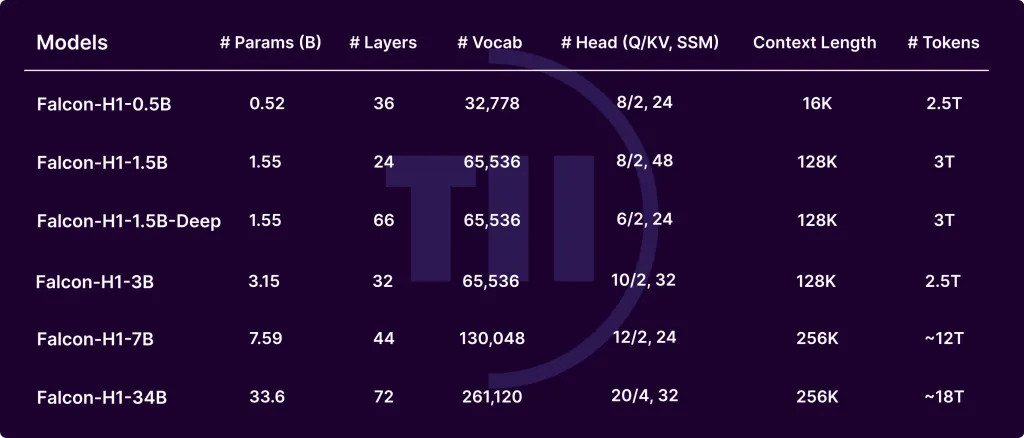
Falcon-H1 Series, developed by Technology Innovation Institute (TII), is a breakthrough in evolution for large language models. Falcon-H1 is able to achieve exceptional performance and memory efficiency by integrating Mamba-based State Space Models with Transformer-based Attention in a hybrid configuration. Falcon-H1 comes in three versions: base, instruct-tuned (and quantized) as well as multiple sizes and parameters (0.5B to 32B). These models offer a better balance between budget and quality.
The Key to Architectural Innovations
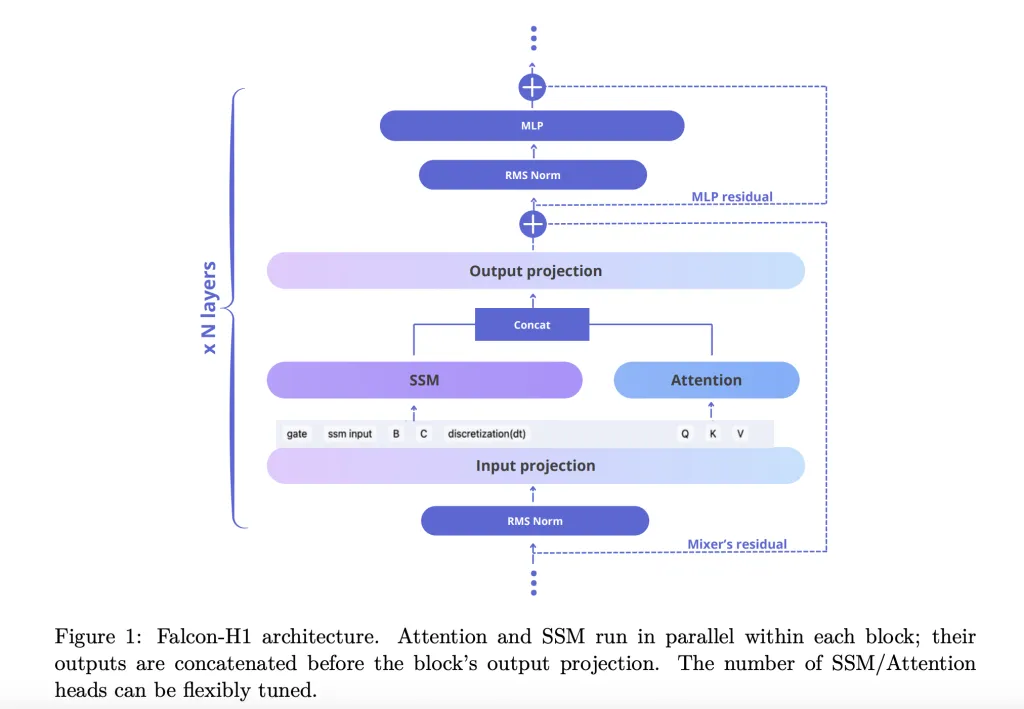
It is important to note that the word “you” means a person. technical report How Falcon-H1 adopted a new technology Parallel hybrid architecture The outputs of both the attention and SSM module are combined before projection. The design is different from the traditional sequential integration, and allows for the tuning of the attention and SSM channel numbers independently. In the default configuration, SSM, MLP, and attention channels are arranged in a 2:1-5 ratio, which optimizes efficiency as well as learning dynamics.

Falcon-H1 further explores to refine the model.
- Channel allocationAblations reveal that increasing the attention channels degrades performance, while balancing SSM/MLP results in robust gains.
- Blocks of different configurationSA_M (semi parallel with SSM and attention run simultaneously, followed by MLP), performs the best on training losses and computation efficiency.
- RoPE base frequencyThe use of a base frequency that is unusually large, 1011 (RoPE), in Rotary Positional Embeddings has been shown to improve generalization when training on long contexts.
- Width-depth trade-offExperiments indicate that deep models perform better than wider ones when parameters are set. Falcon-H1-1.55B-Deep (66) outperforms a number of 3B or 7B models.
Tokenizer Strategy
Falcon-H1 utilizes a custom Byte Pair Encoding suite (BPE), with vocabulary sizes from 32K up to 261K. Key design choices include:
- Separating digits from punctuationImproves code settings and multilingual settings.
- LATEX token injectionModel accuracy is improved on benchmarks in math.
- Multilingual supportCovers up to 18 languages, and can scale from bytes/tokens and optimized fertility metrics.
Data Strategy and the Pre-Training Corpus
Falcon-H1 model is trained using up to 18T of a 20T token collection, which includes:
- Web data of high quality (filtered FineWeb)
- Multilingual datasetsCommon Crawl – Wikipedia, ArXiv and OpenSubtitles. Resources curated for 17 different languages
- The Code Corpsus67 languages processed using MinHash, CodeBERT filters and PII scrubber
- Math datasetsMATH, GSM8K and LaTeX enhanced crawls in house
- Synthetic dataQA textbook style from 30K topics based on Wikipedia.
- Long context sequencesUp to 256K Tokens: Enhance by using Fill-in-the-Middle tasks, synthetic reasoning, and reordering.
The Training Methodologies and Infrastructure
Training utilized customized Maximal Update Parametrization (µP), supporting smooth scaling across model sizes. Advanced parallelism is used in the models:
- Mixer Parallelism (MP) You can also find out more about the following: Context ParallelismEnhance processing throughput of long contexts
- QuantizationReleased in 4-bit and bfloat16 variants for ease of deployment.
Evaluation of Performance
Falcon H1 achieves unmatched performance on every parameter
- Falcon-H1-34B-Instruct surpasses or matches 70B-scale models like Qwen2.5-72B and LLaMA3.3-70B across reasoning, math, instruction-following, and multilingual tasks
- Falcon-H1-1.5B-Deep rivals 7B–10B models
- Falcon-H1-0.5B delivers 2024-era 7B performance
Benchmarks include MMLU and GSM8K tasks as well HumanEval and those with a long context. Models show strong alignment through SFT and Direct Preference Optimization.

You can also read our conclusion.
Falcon-H1 redefines the open-weight LLM by integrating hybrid parallel architectures, tokenization flexibility, training dynamics that are efficient, and robust capabilities for multilingual. SSM combined with attention allows it to deliver unmatched performance in a practical memory and computing budget. It is ideal for both deployment and research across diverse environments.
Click here to find out more Paper You can also find out more about the following: Models on Hugging Face. Please feel free to contact us. check our Tutorials page on AI Agent and Agentic AI for various applications. Also, feel free to follow us on Twitter Don’t forget about our 100k+ ML SubReddit Subscribe Now our Newsletter.

Michal Sutter, a data scientist with a master’s degree in Data Science at the University of Padova. Michal Sutter excels in transforming large datasets to actionable insight. He has a strong foundation in statistics, machine learning and data engineering.