


Alibaba Tongyi Lab research team released ‘Zvec’, an open source, in-process vector database that targets edge and on-device retrieval workloads. It is positioned as ‘the SQLite of vector databases’ because it runs as a library inside your application and does not require any external service or daemon. This is a database designed to run on local laptops, mobile phones, or any other hardware that has limited resources.
It is a simple idea. The core idea is simple. The traditional server-style systems are too heavy to be used by desktop applications, mobile apps or command line utilities. This gap can be filled by an embedded engine which behaves as SQLite, but is designed for embeddings.

RAG: Why the embedded vector search is important?
They need more features than an index. These pipelines need vectors and scalar fields. They also require full CRUD functionality, as well as safe persistence. Local knowledge bases are updated as project notes, files and file states, or even the state of a particular project, change.
Index libraries like Faiss offer approximate closest neighbor searches, but they do not support scalar data storage, crash recovery or hybrid queries. By building your storage and consistency layers, you end up with a solution that is not compatible. DuckDB-VSS, for example, adds vector search capabilities to DuckDB. However it exposes fewer options in terms of indexing and quantization and has a weaker resource management control. Milvus, managed vector clouds and other service-based solutions require multiple network calls as well as separate deployment. These are often too much for tools that run on devices.
Zvec is said to work well in local scenarios. This lightweight library gives you an engine that is vector native, with RAG, persistence and resource management features.
Core Architecture: vector native and in-process
Zvec has been implemented as an embedding library. Install it using Install pip zvec Open collections in Python directly. The RPC and server layers are not external. The Python API allows you to define schemas and insert documents as well as run queries.
Proxima was developed by Alibaba Group and is a high performance vector search tool that has been battle tested. Zvec wraps Proxima in a more simple API with an embedded runtime. This project has been released under an Apache 2.0 licence.
The current support is for Python 3.10 to Python 3.12 under Linux x86_64 and Linux ARM64.
Design goals are clearly stated:
- Execution embedded in the process
- Vector indexing native storage
- Crash safety and production ready persistence
It is suitable for desktop and edge applications as well as zero-ops deployments.
From install to semantic search: the developer workflow
Quickstart documents show a quick path to get from installation to query.
- Installing the Package:
Install pip zvec - Definition of a
CollectionSchemaOne or more vector and optional scalar areas. - Call
create_and_openCreate or open a collection of files on a disk. - Add
DocObjects that have an ID and vectors or scalar attribute. - Create an index, and then run it.
VectorQueryRetrieve your nearest neighbors
Example:
import zvec
# Define collection schema
schema = zvec.CollectionSchema(
name="example",
vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 4),
)
Collection #
collection = zvec.create_and_open(path="./zvec_example", schema=schema,)
# Insert documents
collection.insert([
zvec.Doc(id="doc_1", vectors={"embedding": [0.1, 0.2, 0.3, 0.4]}),
zvec.Doc(id="doc_2", vectors={"embedding": [0.2, 0.3, 0.4, 0.1]}),
])
Find vectors by similarity
Results = collection.query
zvec.VectorQuery("embedding", vector=[0.4, 0.3, 0.3, 0.1]),
topk=10
)
# Results: list of {'id': str, 'score': float, ...}, sorted by relevance
print(results)Results are returned in the form of dictionaries with IDs, similarity scores and IDs. It is sufficient to create a RAG or local semantic retrieval layer over any embedded model.
Performance: VectorDBBench with 8,000+ QPS
Zvec has been optimized to provide high performance and low latencies on CPUs. This includes SIMD and multithreading instructions as well as cache-friendly memory layouts.
The following are some of the ways to get in touch with us VectorDBBench Zvec has reported over 8,000 QPS for the Cohere 10M dataset with similar hardware and matching recall. This is more than 2× the previous leaderboard #1, ZillizCloud, while also substantially reducing index build time in the same setup.
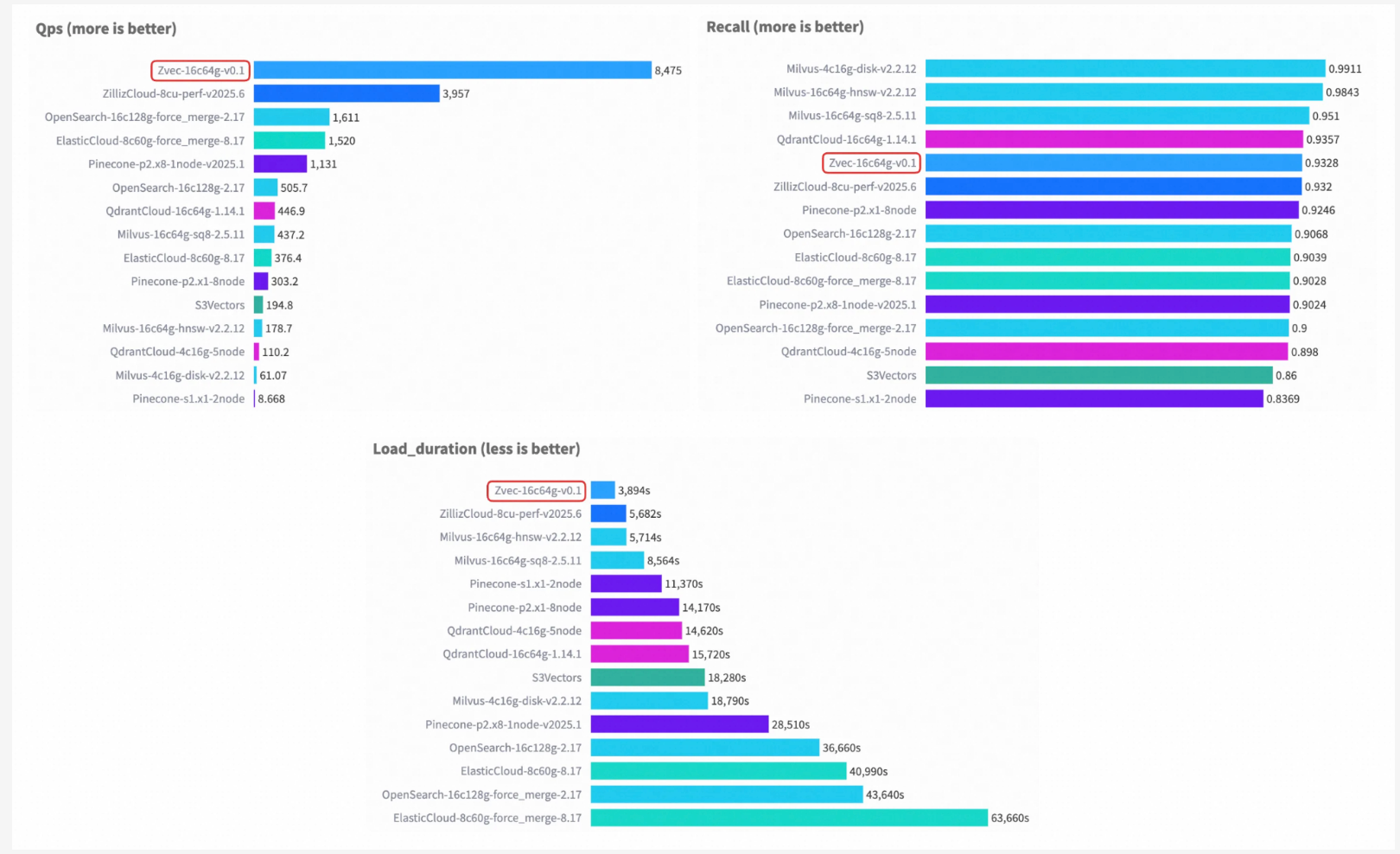
As long as workloads are similar to the benchmark, an embedded library will be able to reach the cloud performance level for high-volume search.
RAG capability: hybrid search, fusion and reranking
This feature set has been tuned to RAG retrieval and agentic retrieval.
Zvec supports:
- Documents can be CRUD-ed to the fullest extent so that local knowledge is always changing.
- The evolution of the index strategy and field schema.
- Retrieve multiple vectors for queries that contain several embedded channels.
- The reranker is built into the software and supports Reciprocal Rank Fusion, weighted fusion.
- Search hybrid combining scalars and vectors, which can be inverted for the attributes of scalars.
It allows for the creation of device assistants with multiple embedded models and filters including user, type, or time.
The Key Takeaways
- Zvec is an embedded, in-process vector database positioned as the ‘SQLite of vector database’ for on-device and edge RAG workloads.
- This application is based upon Proxima – Alibaba’s battle-tested, high-performance vector search engine.
- Zvec delivers >8,000 QPS on VectorDBBench with the Cohere 10M dataset, achieving more than 2× the previous leaderboard #1 (ZillizCloud) while also reducing index build time.
- This engine offers explicit resource management via 64MB stream writes in mmap mode or experimental.
memory_limit_mbThe. and the configurableConnectivity,optimize_threadsThen,query_threadsFor CPU control. - Zvec has a RAG-ready architecture with full CRUD and schema evolution. It also includes multi-vector retrieval (with built-in reranking and RRF) and scalar/vector hybrid search, with an optional inverted index. There is also a roadmap for the ecosystem, which targets LangChain and LlamaIndex as well as DuckDB and PostgreSQL.
Click here to find out more Technical details The following are some examples of how to get started: Repo. Also, feel free to follow us on Twitter Don’t forget about our 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! What? now you can join us on telegram as well.
