


You have probably stared in awe at the progress bar of your GPU cluster as it rolled out rollout generation when you were running reinforcement learning post-training for a language model used to generate code, perform math reasoning or other verifiable tasks. A team of researchers from NVIDIA proposes a precise fix By integrating speculative coding in the RL loop, you can preserve the exact distribution of outputs for the model.
Researchers integrated decoding directly in the code. NeMo RL v0.6.0 With a vLLM-based backend that delivers lossless acceleration for both the 8B scale and the projected 235B, this latest NeMo RL v0.6.0 is now shipping speculative encoding, along with the SGLang optimization engine, YaRN’s long context training, as a feature.

The bottleneck is Rollout Generation
It is important to understand how a synchronous RL step works. NeMo RL is divided into steps. Five stagesData loading (prepare), weight synchronization (synchronize) and preparation of the backend (prepare), generation of rollouts (gen), recomputation logprobability (logprob), policy optimization (train).

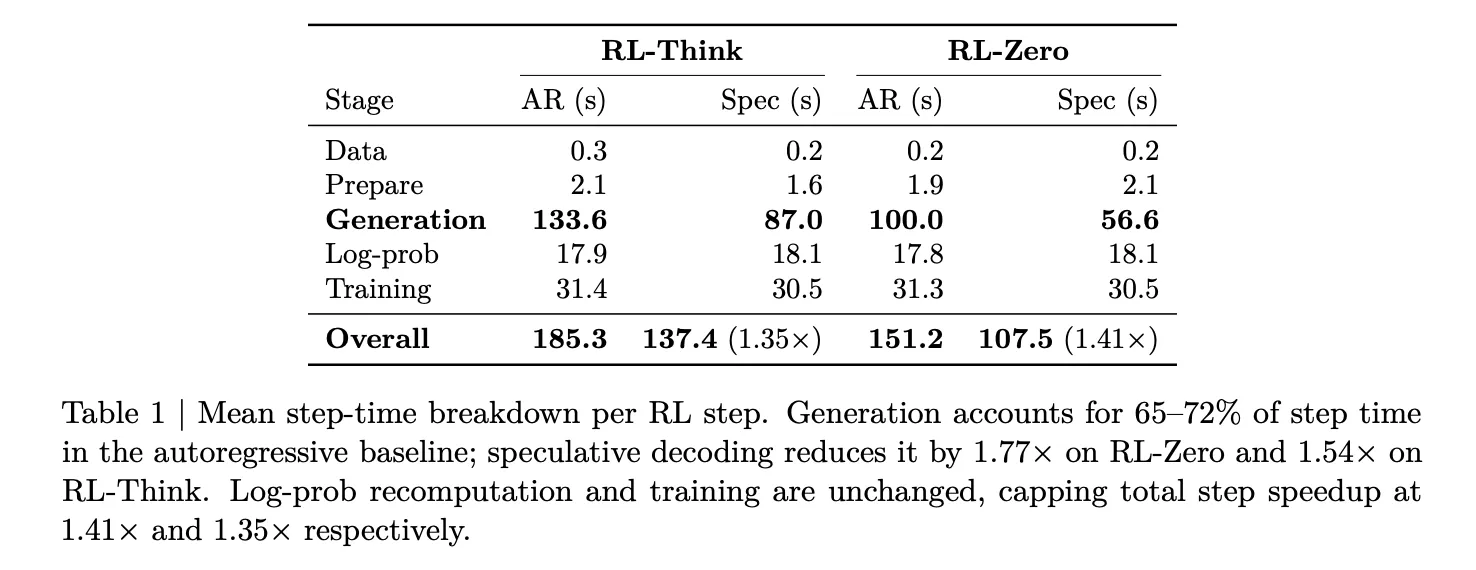
This breakdown was measured by the research team on Qwen3-8B below. two workloads — RL-ThinkThe model is trained to be able to reason. RL-ZeroThe model starts at a simple base and builds reasoning by itself. In both cases, rollout generation accounts for 65–72% of total step time. Log-probability recomputation and training together take only about 27–33%. The only step that is worth accelerating for rollout side optimization, therefore, is generation.
What Speculative Decodification Actually Does
The technique of speculative decoding involves the use of a faster, smaller code. Models for a draft When you propose several tokens, the bigger they are. Target model The model you’re actually training verifies the tokens using a sampling rejection procedure. This rejection method is guaranteed mathematically to generate the same output distribution that would have been produced if those tokens had been generated autoregressively by the model. There is no mismatch in distribution, and no need for off-policy adjustments. The training signal remains unchanged.
It is crucial to note that in RL, post-training the reward for training depends on samples from the policies themselves. The methods like low-precision rolls out, off-policy playback, or asynchronous implementation all compromise some of the training fidelity in order to increase throughput. The rollouts produced by speculative decoding are the same as what would be generated by the model on its own. They’re just faster.
System Integration Challenge
Addition of draft models to the backend for a server is simple. It’s not easy to add a draft model to RL. The rollout engine should be updated every time there is a policy update. It is important that the draft model remains aligned to evolving policies. All log-probabilities and KL penalties must be calculated using the actual (verifier policy) not a draft. Otherwise, the optimization goal is corrupted.
This is handled by the NVIDIA Research Team in NeMo RL. Two-path Architecture. A general path can also be created using EAGLE-3. It is a drafting tool that supports any pre-trained model and does not require native support for multi-token predictions (MTP). There is a native pathway for models which ship with MTP head. If online draft adaption is enabled, hidden states and log probabilities from MegatronLM’s forward pass will be cached, and then used to supervise the Draft Head via a gradient detach pathway. This ensures that draft training does not interfere with policy gradient signals.
Measuring Results on the 8B Scale
On 32 GB200 GPUs (8 GB200 NVL72 nodes, 4 GPUs per node), EAGLE-3 reduces generation latency from 100 seconds to 56.6 seconds on RL-Zero — a 1.8× generation speedup. On RL-Think, it drops from 133.6 seconds to 87.0 seconds, a 1.54× speedup. Because log-probability re-computation and training are unchanged, these generation-side gains translate to overall step speedups of 1.41× on RL-Zero and 1.35× on RL-Think. The validation accuracy of AIME-2024 changes in the same way under both autoregressive decoding and speculative re-computation throughout training. This confirms that lossless guarantees are valid.
Researchers also test n-gram writing as a baseline speculative without a model. Despite achieving acceptance lengths of 2.47 on RL-Zero and 2.05 on RL-Think, n-gram drafting is slower than the autoregressive baseline in both settings — 0.7× and 0.5× respectively. The conclusion is critical for practitioners. A positive acceptance length alone is not enough. Speculation can be made worse if the overhead of verification is too high.
How to Get the Most Out of Your Speedup
Researchers isolate a number of toxins Three operational options What practitioners need to do right
Draft initialization It is more important to have a good drafting skill than a generic one. An EAGLE-3 draft initialized on the DAPO post-training dataset achieves a 1.77× generation speedup on RL-Zero, while a draft initialized on the general-purpose UltraChat and Magpie datasets achieves only 1.51× at the same draft length. Drafts must match the real-world rollout distribution, and not simply a chat distribution.
Draft length It has an optimum that is not obvious. At draft length k=3, RL-Zero achieves 1.77× speedup and RL-Think achieves 1.53×. Increasing to k=5 raises the acceptance length but drops speedup to 1.44× on RL-Zero and 0.84× on RL-Think — the latter already slower than autoregressive. At k=7, RL-Zero drops further to 1.21× and RL-Think to 0.71×. It’s important to note the contrast: RL-Zero generates its rollouts from a model that starts with short outputs. This makes it easier to guess at even high k. RL-Think, on the other hand, has reasoning traces which are more complex and harder to guess. The overhead associated with longer drafts can quickly erase the benefits. The overhead of longer drafts can quickly erase any benefit from higher acceptance, particularly in generation regimes that are more difficult.
Online draft adaptation — updating the draft during RL using rollouts generated by the current policy helps most when the draft is weakly initialized. For a DAPO-initialized draft, offline and online configurations perform nearly identically (1.77× vs. 1.78× on RL-Zero). For a UltraChat-initialized draft, online updating improves speedup from 1.51× to 1.63× on RL-Zero.
Asynchronous interaction with the execution The 8B-scale was tested in real time, not only through simulation. In a non-colonized 16-node configuration with 12 nodes allocated to generation, and four to training, the research team tested RL-Think in policy lag 1. The majority of the rollout generation in asynchronous mode is hidden by log-probability updates and policy updates. Therefore, the quantity that is relevant is the remaining exposed generation time on the critical pathway. Speculative decoding reduces that exposed generation time from 10.4 seconds to 0.6 seconds per step and lowers effective step time from 75.0 seconds to 60.5 seconds (1.24×). The gain is smaller than in synchronous RL — expected, since asynchronous overlap already hides much of the rollout cost — but it confirms that the two mechanisms are genuinely complementary rather than redundant.
Estimated Gains on 235B Scale
Using an exclusive GPU performance simulation calibrated according to the device’s compute, interconnect, and memory characteristics, researchers projected decoding gains at greater scales. For Qwen3-235B-A22B running synchronous RL on 512 GB200 GPUs, draft length k=3 with an acceptance length of 3 tokens yields a 2.72× rollout speedup and a 1.70× end-to-end speedup.
At the most favorable simulated operating point — Qwen3-235B-A22B on 2048 GB200 GPUs with asynchronous RL at policy lag 2 — rollout speedup reaches approximately 3.5×, translating to a projected 2.5× end-to-end training speedup. The complementary nature of speculative decoding with asynchronous execution is described: speculation lowers the costs for each rollout while the asynchronous overlap hides remaining generation times behind log-probability and training.
What you need to know
- The bottleneck is rollout generation in RL after-training, accounting for 65–72% of total step time in synchronous RL workloads — making it the only stage where acceleration has meaningful impact on end-to-end training speed.
- EAGLE-3 speculative decoding provides lossless acceleration via rollout, achieving 1.8× generation speedup at 8B scale (1.41× overall step speedup) without changing the target model’s output distribution — unlike asynchronous execution, off-policy replay, or low-precision rollouts, which all trade training fidelity for throughput.
- The quality of the initialization is more important than the draft length, with in-domain (DAPO-trained) drafts outperforming general chat-domain drafts by a meaningful margin; longer draft lengths (k≥5) consistently backfire in harder reasoning workloads, making k=3 the reliable default.
- Gains scaled up dramatically in simulations, reaching ~3.5× rollout speedup The following are some examples of how to get started: a projected ~2.5× end-to-end training speedup at 235B scale on 2048 GB200 GPUs — and the technique is already available in NeMo RL v0.6.0 under Apache 2.0.
Check out the Full Paper and Nemo RL Repo. Also, feel free to follow us on Twitter Join our Facebook group! 130k+ ML SubReddit Subscribe Now our Newsletter. Wait! What? now you can join us on telegram as well.
You can partner with us to promote your GitHub Repository OR Hugging Page OR New Product Launch OR Webinar, etc.? Connect with us