


How can you integrate SigLIP2, DINOv3, SAM3, and other vision models into a single backbone, without sacrificing performance in dense segmentation or dense encoding? NVIDIA C-RADIOv4 combines three powerful teacher models SigLIP2-g-384 DINOv3-7B and SAM3 into a student encoder. The AM-RADIO line is extended, while maintaining similar computation costs, improving dense predictions, robustness of resolution, and dropping-in compatibility for SAM3.
Simple is the key. C-RADIOv4 tries, with a single backbone, to approximate the three models simultaneously: a vision model language, a dense self-supervised model and a segmentation.

Agglomerative distillation in RADIO
The RADIO family is used agglomerative distillation. The ViT-style student learns to compare dense feature maps with summary tokens provided by several teachers.
Earlier RADIO versions combined DFN CLIP with DINOv2 and SAM. They already supported multi resolution training but showed ‘mode switching’, where the representation changed qualitatively as input resolution changed. PHI, RADIOv2.5, FeatSharp and other later work improved multi-resolution distillation and regularization but still had a limited teacher set.
Teachers can upgrade to C-RADIOv4:
- SigLIP2-g-384 for stronger image text alignment
- DINOv3-7B For high-quality self-supervised dense features
- SAM3 Compatible with SAM3 and segmentation-oriented features
This student’s dense tokens are matched to DINOv3 or SAM3, and its summary tokens are matched to SigLIP2 or DINOv3. It is possible to create an encoder which can perform classification, retrieval dense prediction and segmentation.
Multi-resolution training with stochastic multi resolution
C-RADIOv4 is based on stochastic resolution training, rather than a fixed number of resolutions.
Two partitions of input sample sizes:
- Low Resolution:
{128, 192, 224, 256, 384, 432} - High resolution
{512, 768, 1024, 1152}
SigLIP2 runs natively in 384 pixels. FeatSharp is used to upsample its features by 3 times in order to match them with SAM3’s 1152-pixel features. SAM3 is trained with mosaic augmentation at 1152 × 1152.
It also improves performance at low resolution. On ADE20k, linear probing is an example. C-RADIOv4-H Reach around
- The 55.20 mIoU for a 512px image is
- The 57.02 mIoU is at 1024 pixels
- At 1536 pixels, 57.72mIoU is displayed.
This scaling pattern is very similar to DINOv3-7B, but with fewer parameters.
MESA and shift-equivalent losses to remove teacher noise
It is not only the useful structure that can be copied, but also their artifacts. ViTDet-style models, such as SigLIP2, can display window border artifacts. Direct feature regression forces the student to replicate those patterns.
C-RADIOv4 uses two equivariant shift mechanisms to eliminate such noise.
- Shift equivariant dense lossEvery teacher and student should see Independently shifted Images can be cropped. Prior to computing the squared errors, the features are aligned using a shift map and only overlapping spatial locations are used for the loss. The student will never be able to see the exact same positions as their teacher. This means that they cannot memorize absolute noise. Instead, the student must track input-dependent structure.
- MESA shift equivariantC-RADIOv4 regularizes the network online and the EMA version using MESA. The student’s EMA and C-RADIOv4 see different crops. Features are aligned with a shift and the loss applied after normalization of the layer. The result is a robust and smooth terrain with no change in absolute position.
DAMP is also used in training to add multiplicative noises into the weights. It also improves the robustness of weights to small shifts in distribution and corruptions.
Summary loss with angular dispersion in mind for teachers to balance
In previous RADIO-based models, the summation loss was calculated using cosine between embeddings of student and teacher. Cosine distance removes magnitude but not Directional dispersion The sphere. Some teachers such as SigLIP2 produce embedded images that are concentrated into a cone. DINOv3 produces more dispersed embeddings.
When using raw cosine, the teachers who have a wider dispersion of angular angles contribute more losses to optimization and are dominant. In summary, DINOv3 tended in practice to be more dominant than SigLIP2.
C-RADIOv4 will replace this word with Angle normalized loss. This is the result of dividing the squared angle (between student and teacher embeddings) by the teacher’s angular distribution. SigLIP2-g-384 dispersion is around 0.694. DINOv3-7B, DINOv3-7B-H+ are both around 2.12 and 2.19. These values are used to normalize the dispersion of each and maintain both vision language as well as dense semantics.
Performance: Classification, dense predictions, and Probe3d
You can find out more about this by clicking here. ImageNet-1k zero shot classificationAbout. C-RADIOv4H is able to reach 83.09 % top-1 accuracy. The performance is comparable to or better than RADIOv2.5 and C-RADIOv3 at all resolutions.
You can find out more about this by clicking here. Classification k-NNC-RADIOv4 is superior to RADIOv2.5 or C-RADIOv3, while DINOv3 starts at 256 px and can be matched, if not surpassed. DINOv3 peaks near 192–256 px and then degrades, while C-RADIOv4 keeps stable or improving performance at higher resolutions.
The intended trade-off is based on dense and 3D metrics. C-RADIOv4H, the SO400M, and PASCAL VOC are comparable with DINOv3-7B and outperform previous RADIO versions on dense benchmarks. The typical score for C-RADIOv4H is:
- The ADE20k is 55.20mIoU
- VOC : 87.24 mioU
- NAVI: 63.44
- SPair: 60.57
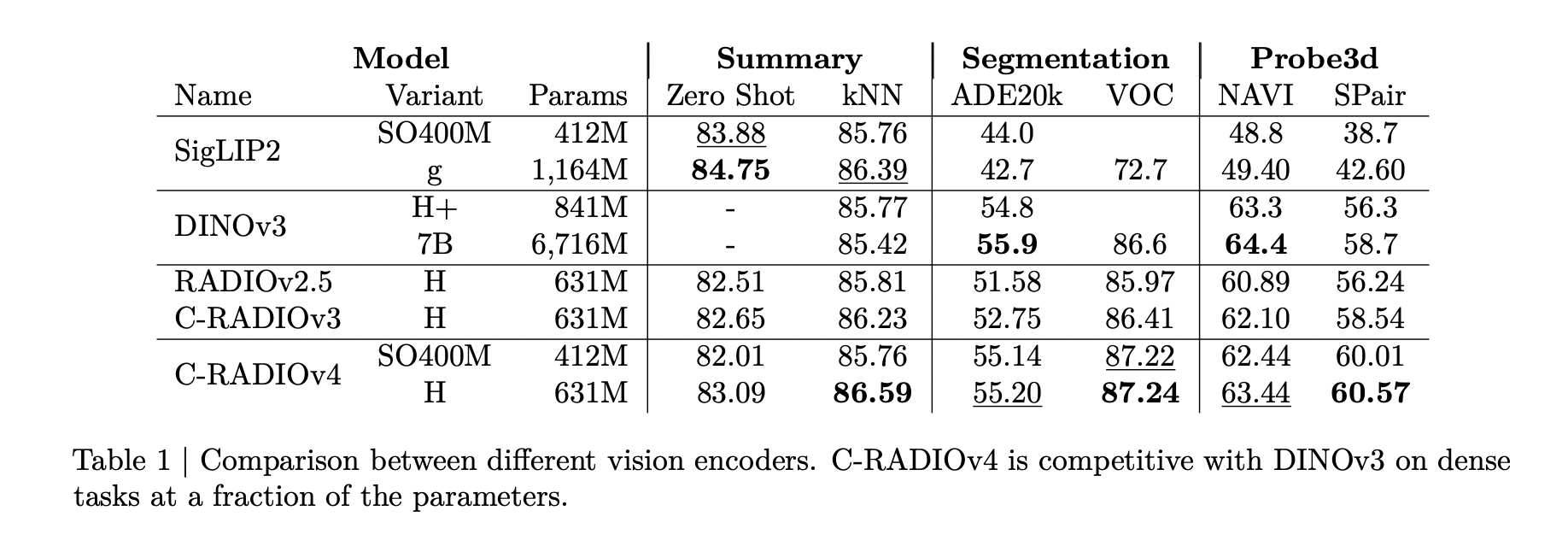
You can find out more about this by clicking here. Probe3dC-RADIOv4 achieves the highest level of performance with depth and surface normals as well as NAVI. NAVI You can also find out more about the following: SPair The RADIO score is a good indicator of the quality. The Depth and Surface metrics of C-RADIOv3 are very similar, but with slight differences.
Integration of SAM3 with ViTDet mode deployment
C-RADIOv4 was designed as a direct replacement of the Perception Encoder in SAM3. SAM3’s decoder and memories remain the same. The SAM3 implementation includes a sample reference. Examples qualitatively show how segmentation is maintained for text prompts like “shoe”, “helmet”, “bike”, “spectator” SAM3 based C-RADIOv4 has been reported to resolve failure cases of the encoder.
For deployment, C-RADIOv4 exposes a ViTDet-mode configuration. The majority of transformer blocks are windowed, but a small number use global attention. Supported window sizes range from 6 × 6 to 32 × 32 tokens, subject to divisibility with patch size and image resolution. The SO400M encoder with a window size of 12 or less is quicker than the SAM3 via-L+ encoder for a variety of input sizes.
C-RADIOv4 is a good choice for tasks requiring high levels of resolution and where the cost to pay full attention across all layers would be prohibitive.
What you need to know
- One single backbone C-RADIOv4 combines SigLIP2-g-384 and DINOv3-7B into a ViT encoder which supports segmentation, prediction and dense classification.
- Any-resolution behavior: Stochastic multi resolution training over {128…1152} px, and FeatSharp upsampling for SigLIP2, stabilizes performance across resolutions and tracks DINOv3-7B scaling with far fewer parameters.
- Noise suppression via shift equivariance: MESA and Shift Equivariant Dense Loss prevent students from copying border or window artifacts. This allows them to focus on learning input-dependent semantics.
- Distillation with multiple teachers: A normalized angular distribution summary loss balances out the contribution from SigLIP2 versus DINOv3, preserving alignment of text and dense presentation quality.
- SAM3 deployment and ViTDet ready: C-RADIOv4 is a replacement for the SAM3 perception encoder. It offers ViTDet windowed attention to speed up high resolution inference and it’s released under NVIDIA OpenModel License.
Click here to find out more Paper, Repo, Model-1 You can also find out more about the following: Model-2. Also, feel free to follow us on Twitter Don’t forget about our 100k+ ML SubReddit Subscribe Now our Newsletter. Wait! Are you using Telegram? now you can join us on telegram as well.
