


Alibaba released Qwen3-Max – a Mixture-of-Experts model with a trillion-parameters, positioned as the most powerful foundation model it has ever created. It is available to public immediately via Qwen Chat, and Alibaba Cloud Model Studio API. This launch takes Qwen 2025 from preview into production, and focuses on two versions: Qwen3-Max-Instruct Standard reasoning/coding problems and Qwen3-Max-Thinking For tool-added “agentic” workflows.
The latest model updates?
- Scale & architectureThe Qwen3 Max has crossed the 1 trillion-parameter threshold with a MoE (sparsely activated tokens). Alibaba claims that the system is its most powerful and capable model to date. In public briefings as well as media reports, it’s consistently referred to as 1T class rather than just another midscale refresh.
- Running/training postureQwen3-Max is designed with sparse Mixture-of-Experts and has been pre-trained. ~36T tokens (~2× Qwen2.5). The corpus tends to be a bit more towards The STEM/reasoning approach, multilingualism and coding data. Post-training follows Qwen3’s four-stage recipe: long CoT cold-start → reasoning-focused RL → thinking/non-thinking fusion → general-domain RL. Alibaba confirms >1T parameters For Max, treat token count/routing until an official Max Tech report has been published.
- You can access this page by clicking here.Model Studio is a tool that enables inference, whereas Qwen Chat shows the UX of general purpose. “thinking mode” toggles (notably,
incremental_output=trueQwen3 Thinking Models). Model Studio has a list of models and their prices, with a region-specific availability.
Benchmarks: math, coding and agentic control
- Coding (SWE-Bench Verified). Report Qwen3 – Max Instruct at 69.6 SWE Bench Verified. This puts it slightly above Claude Opus 4, which is a non-thinking baseline (e.g. DeepSeek V3.1). Consider these numbers as a snapshot; the SWE-Bench evaluates harnesses quickly.
- Use of Agentic Tool (Tau2-Bench) Qwen3 max posts 74.8 on Tau2-Bench—an agent/tool-calling evaluation—beating named peers in the same report. Tau2 tests decision-making, tool routing and not only text accuracy. Gains here can be meaningful to workflow automation.
- Math & advanced reasoning (AIME25, etc.). You can also find out more about the following: Qwen3-Max-Thinking Track (with Tool Use and A “heavy” In multiple secondary sources, and in earlier coverage of the previews, runtime configuration is described as being near-perfect for key math benchmarks. The official technical report is not expected to be released until the end of this month. “100%” claims as vendor-reported or community-replicated, not peer-reviewed.

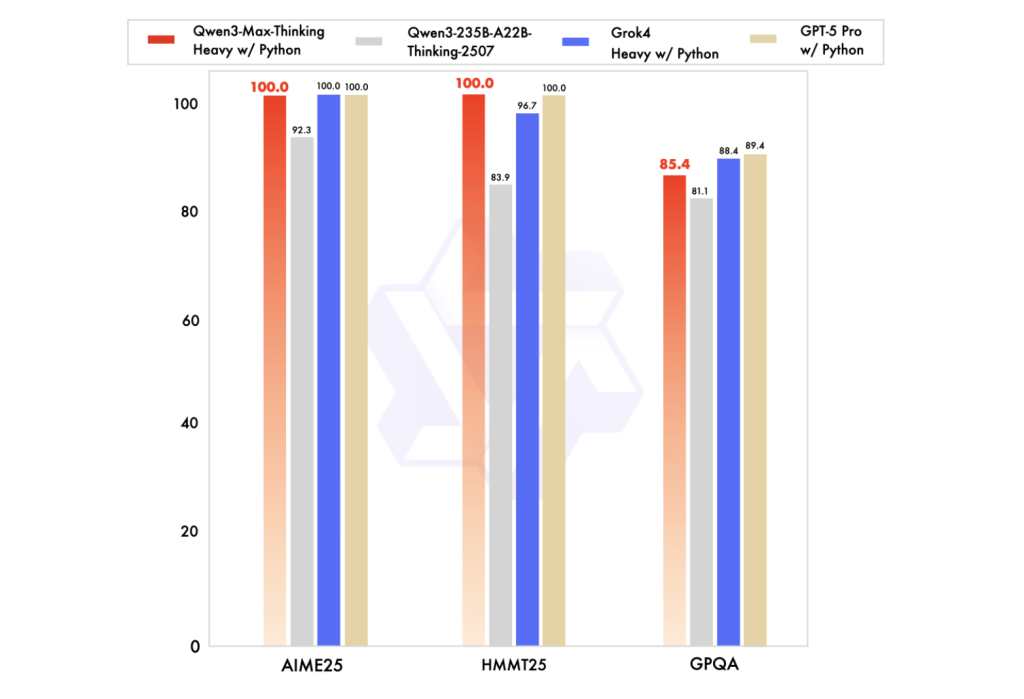
Why two tracks—You can also Instruct vs. Think about it?
Instruct targets conventional chat/coding/reasoning with tight latency, while Thinking This enables longer deliberation trails and explicit tool calling (retrievals of code, execution, browsing, evaluations), with the aim of higher reliability “agent” Use cases. Alibaba API documentation is important because it formalizes runtime switches. Only Qwen3 models that support streaming increment output can be usedCommercial defaults are The same applies to the use of falseCallers will have to set this option explicitly. This is a small but consequential contract detail if you’re instrumenting tools or chain-of-thought-like rollouts.
What to do when you are unsure about your gains??
- Coding: A 60–70 SWE-Bench Verified score range typically reflects non-trivial repository-level reasoning and patch synthesis under evaluation harness constraints (e.g., environment setup, flaky tests). These deltas are more important than single-file code toys if your work depends on large-scale changes to the source code.
- Agentic: Tau2-Bench focuses on multi-tool selection and planning. The improvements here will usually result in fewer fragile hand-crafted policy in the production agents, if your tool APIs or execution sandboxes have been robust.
- Math/verification: “Near-perfect” Calculators and validators are useful tools to help you with math problems. It depends on how you design your evaluation tool and the guardrails if those gains can be transferred to other tasks.
You can read more about it here:
Qwen3-Max is not a teaser—it’s a deployable 1T-parameter MoE with documented thinking-mode semantics and reproducible access paths (Qwen Chat, Model Studio). Treat day-one benchmark wins as directionally strong but continue local evals; the hard, verifiable facts are scale (≈36T tokens, >1T params) and the API contract for tool-augmented runs (incremental_output=true). This is ready to be used for internal gated testing and hands-on trial against SWE/Tau2 style suites by teams developing coding systems and agentic systems.
Take a look at the Technical details, API The following are some examples of how to get started: Qwen Chat. Please feel free to browse our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter Join our Facebook group! 100k+ ML SubReddit Subscribe now our Newsletter.
Asif Razzaq, CEO of Marktechpost Media Inc. is a visionary engineer and entrepreneur who is dedicated to harnessing Artificial Intelligence’s potential for the social good. Marktechpost was his most recent venture. This platform, which focuses on machine learning and deep-learning news, is technically solid and accessible to a broad audience. Over 2 million views per month are a testament to the platform’s popularity.