


As an exciting alternative to the traditional autoregressive large language models, diffusion-based models are currently being studied. They offer simultaneous token generation. These models use bidirectional attention mechanisms to speed up decoding and provide faster inferences than autoregressive methods. Even though they promise to be faster, diffusion models are often unable to achieve this in reality.
Inefficient inference is the primary problem in diffusion-based LLMs. The models do not typically support the key-value cache mechanism, which is essential to accelerate inference through the reuse of previously computed states. Every new generation in diffusion models requires full attention calculations, which is computationally expensive. Further, when decoding multiple tokens simultaneously—a key feature of diffusion models—the generation quality often deteriorates due to disruptions in token dependencies under the conditional independence assumption. Diffusion models are therefore unreliable in practice, despite the theoretical advantages.
In order to improve diffusion LLMs, efforts have been focused on strategies such as block-wise generation or partial caching. LLaDA, Dream and other models use masked diffusion to make multi-tokens easier. They still do not have an efficient key-value cache, which is why parallel decoding often leads to incoherent results. These methods add additional complexity to the models, without addressing any of the fundamental performance problems. Diffusion LLMs still have a slower generation speed than autoregressive LLMs.
Fast-dLLM is a framework that was developed by researchers from NVIDIA and The University of Hong Kong. It addresses these limitations, without requiring retraining. Fast-dLLM introduces two new innovations for diffusion LLMs, a blockwise approximate KV cache mechanism and a confident parallel decoding strategy. It is designed to take advantage of the bidirectional nature diffusion models. The activation from previous steps can be reused with efficiency. This confidence-aware parallel model decodes only tokens that meet a certain confidence level, thus reducing the errors caused by token independence. It is a good compromise between quality and speed, which makes it an ideal solution for text generation tasks based on diffusion.
By dividing the sequences into different blocks, Fast-dLLM implements its KV Cache in depth. Prior to generating a new block, the KV activations from previous blocks are calculated and stored. They can then be reused during decoding. Cache updates are performed after each block is generated, minimizing computations while maintaining accuracy. DualCache extends the approach to cache both prefixes and suffixes. This takes advantage of the high degree of similarity in adjacent inferences steps as shown by heatmaps for cosine similarity in this paper. The system decodes tokens that are above a certain threshold based on the evaluation of their confidence. The system prevents any dependency violation from the simultaneous sampling. This ensures a better quality of generation, even when several tokens are encoded at once.
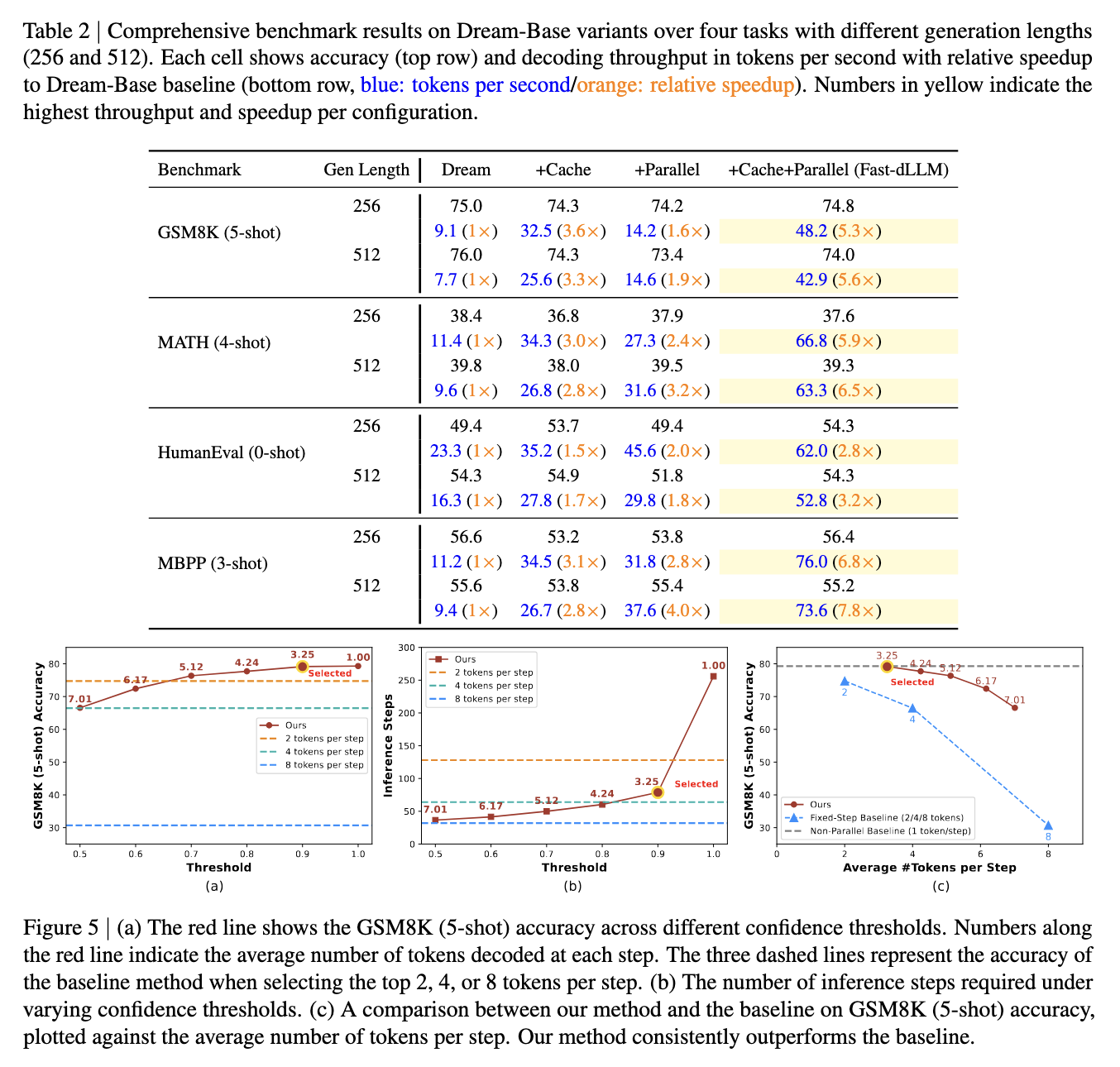
In benchmark tests, Fast-dLLM showed significant improvements. On the GSM8K dataset, for instance, it achieved a 27.6× speedup over baseline models in 8-shot configurations at a generation length of 1024 tokens, with an accuracy of 76.0%. On the MATH benchmark, a 6.5× speedup was achieved with an accuracy of around 39.3%. The HumanEval benchmark saw up to a 3.2× acceleration with accuracy maintained at 54.3%, while on MBPP, the system achieved a 7.8× speedup at a generation length of 512 tokens. Across all tasks and models, accuracy remained within 1–2 points of the baseline, showing that Fast-dLLM’s acceleration does not significantly degrade output quality.
By introducing an innovative caching strategy, and a confidence driven decoding method, the research team was able to effectively address core bottlenecks of diffusion-based LLMs. By improving the decoding process and decreasing inference errors, Fast-dLLM shows how diffusion LLMs are able to match or surpass auto-regressive models for speed. They also maintain high accuracy.
Take a look at the Paper You can also find out more about the following: Project Page . This research is the work of researchers. Also, feel free to follow us on Twitter Join our Facebook group! 95k+ ML SubReddit Subscribe now our Newsletter.
Nikhil works as an intern at Marktechpost. He has a dual integrated degree in Materials from the Indian Institute of Technology Kharagpur. Nikhil, an AI/ML fanatic, is constantly researching AI/ML applications for biomaterials and other biomedical fields. Material Science is his background. His passion for exploring and contributing new advances comes from this.
